
SQL to dbt guide: How Data Layers Flow With Medallion
Let's go through how dbt uses Medallion architecture to come up with nicely organised projects.

Hi there! Alejandro here 😊
Suscribe if you like to read about technical data & AI learnings, deep dives!
Enjoy the reading and let me know in the comments what you think about it 👨🏻💻
📝 TL;DR
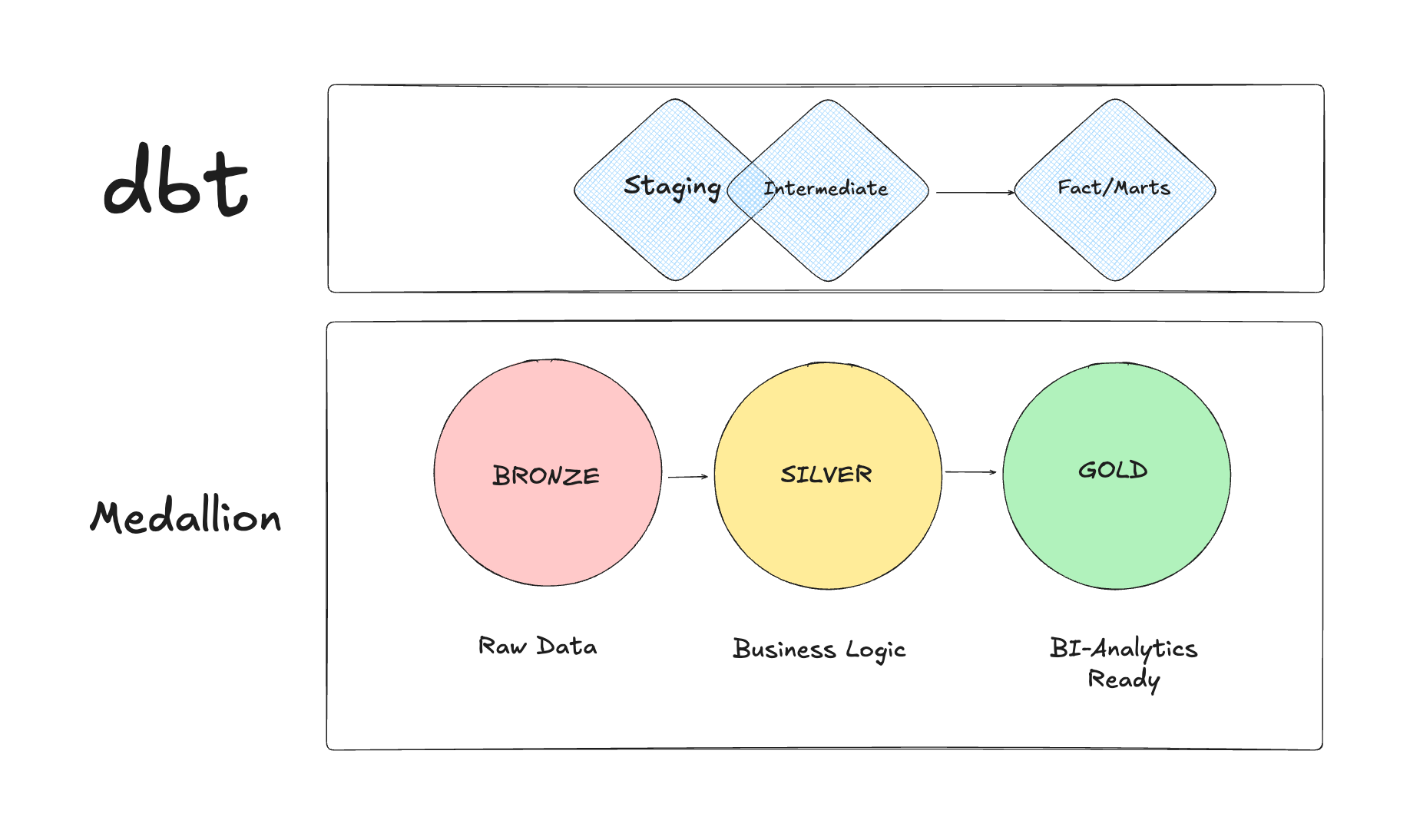
(Bronze/Silver/Gold) organizes dbt projects into logical transformation layers, not just folders
Raw data sources and staging models that clean and standardize without business logic
Intermediate models where business rules, joins, and calculations happen
Analytics-ready marts that business users actually query for decision-making
Clear separation of concerns, easier testing and debugging, better maintainability as your project scales
Over-engineering layers when simple staging → marts flow would work fine
Remember: It’s about finding what works for your team, not following rules strictly
Following up with our SQL to dbt series, now is the turn of talking about layers, specifically about Medallion. You can know more about the series starting here:


Yes, Medallion architecture might look like a nice way of organizing folders, but it's more than that.
You create logical flows of data transformations that makes sense to your team and scales with your business.
The further you go up, the cleaner and complexity-free the project should be.
You can break down business logic into useful transformed assets from source to final analytics ready assets.
And the good thing about dbt is that a good project is documentation on itself.
The medallion pattern (Bronze/Silver/Gold) has become the standard for modern data platforms, but it's not about following rules strictly.
You need to find what makes sense for your use cases and maintain those transformation patterns since that will help every time you need to add, modify or even remove data models; new team members onboarding sucess rely on having a good project setup.
You can read how Databricks defines the concepts here.
It's important to clarify that Data modeling is something different. The fact that dbt has “models” doesn't mean that you are doing data modeling just by using it.
Medallion comes in handy as a data design pattern to organize data blocks to make the output BI ready to consume afterwards.

Let's trace how raw campaign data becomes actionable business intelligence through proper layering.
Remember you can follow all the examples in the sql-to-dbt-series repo.

💡 dbt Patterns vs Medallion Architecture
There’s an important distinction to make before we start.
What Medallion architecture (MA) calls Bronze is sometimes mistaken to what dbt calls “staging” models.
The main difference between both of them is that dbt could already be doing some basic processing on staging models while Bronze layer on MA is just raw data.
MA Silver layer is a fair equivalent to intermediate dbt layer, same with MD gold layer to fact/marts dbt layer.
Bronze Layer: The Foundation 🥉
Your sources.yml file defines the contract between dbt and raw data:
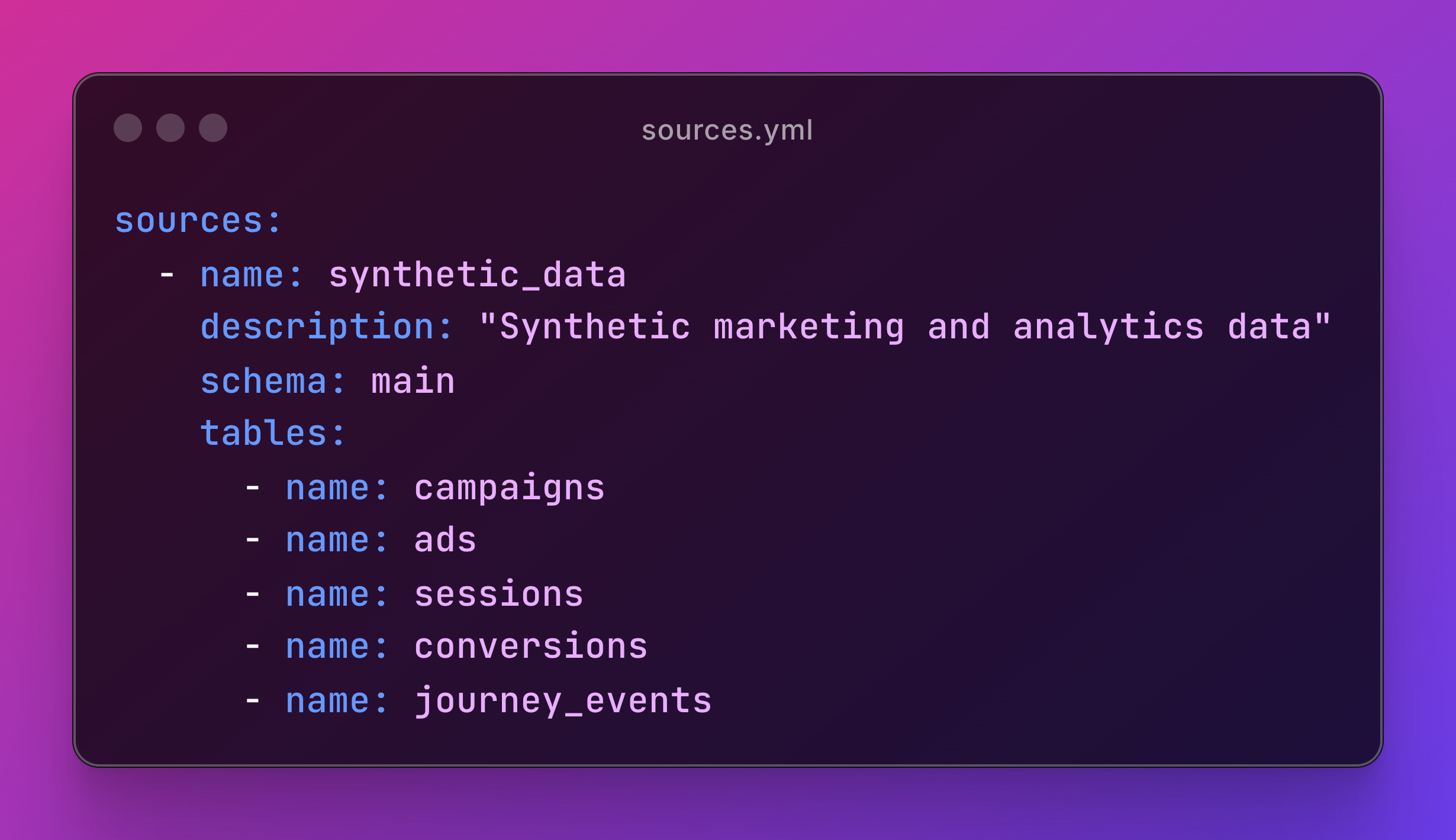
This is your Bronze layer raw data with minimal transformation.
The source() function creates dependency management that everything else builds upon. No business logic here, just clean access to your raw tables.
You can go fancy here and test things you want to validate from the backend tables even before transforming anything.
Silver Layer: Business Logic 🥈
From a dbt perspective, what comes after this Bronze layer are known as staging models.
Clean raw data without adding business logic. Look at stg_campaigns.sql:
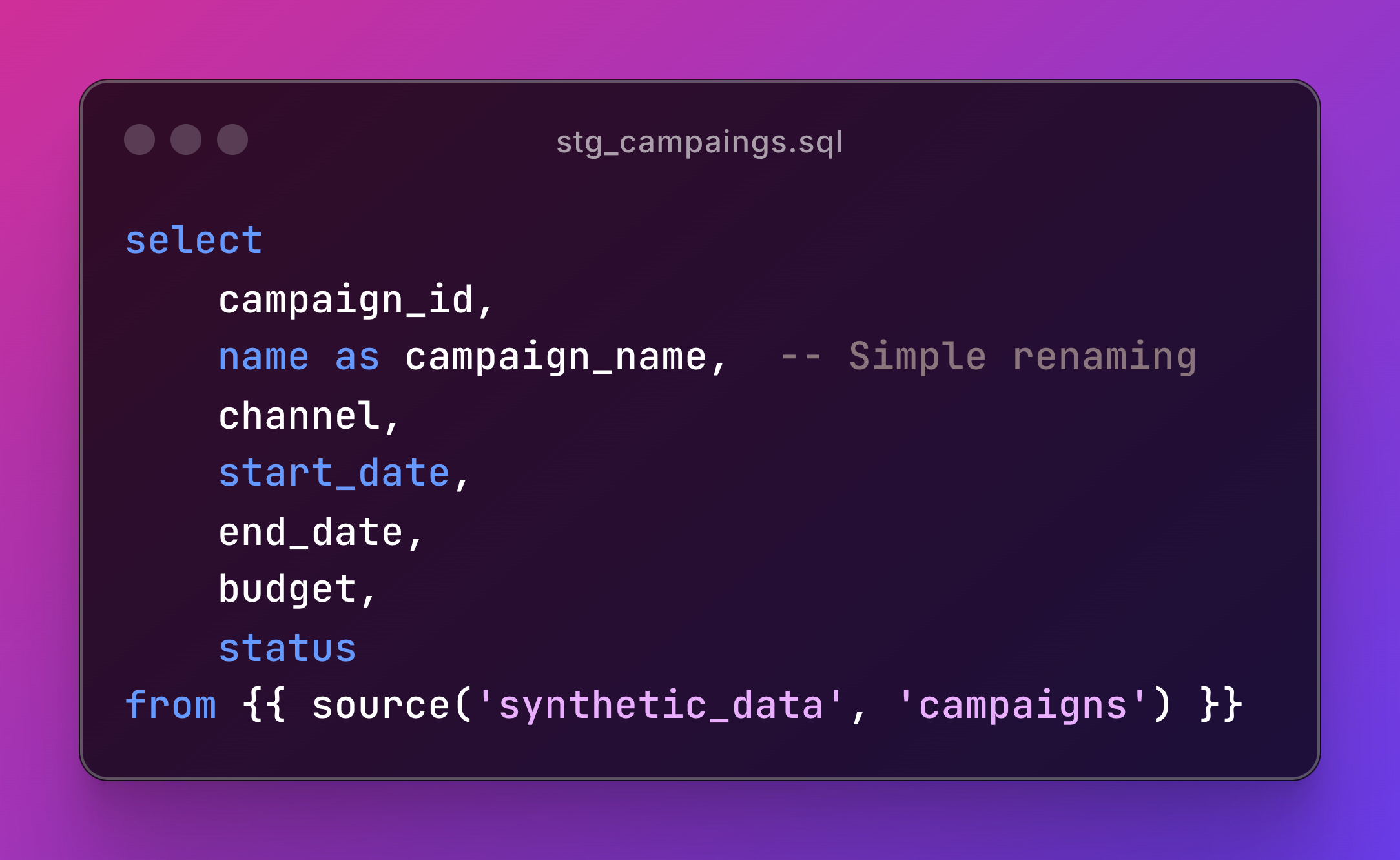
Notice what’s NOT here: no aggregations, no complex CASE statements, no joins. Staging models standardize column names, handle data types, and ensure consistency.
Each staging model represents should represent one source table for consistency, cleaned and ready for business logic.
This separation makes debugging infinitely easier when things break.
Then we start going fancy and apply some logic into models with dbt intermediate layer.
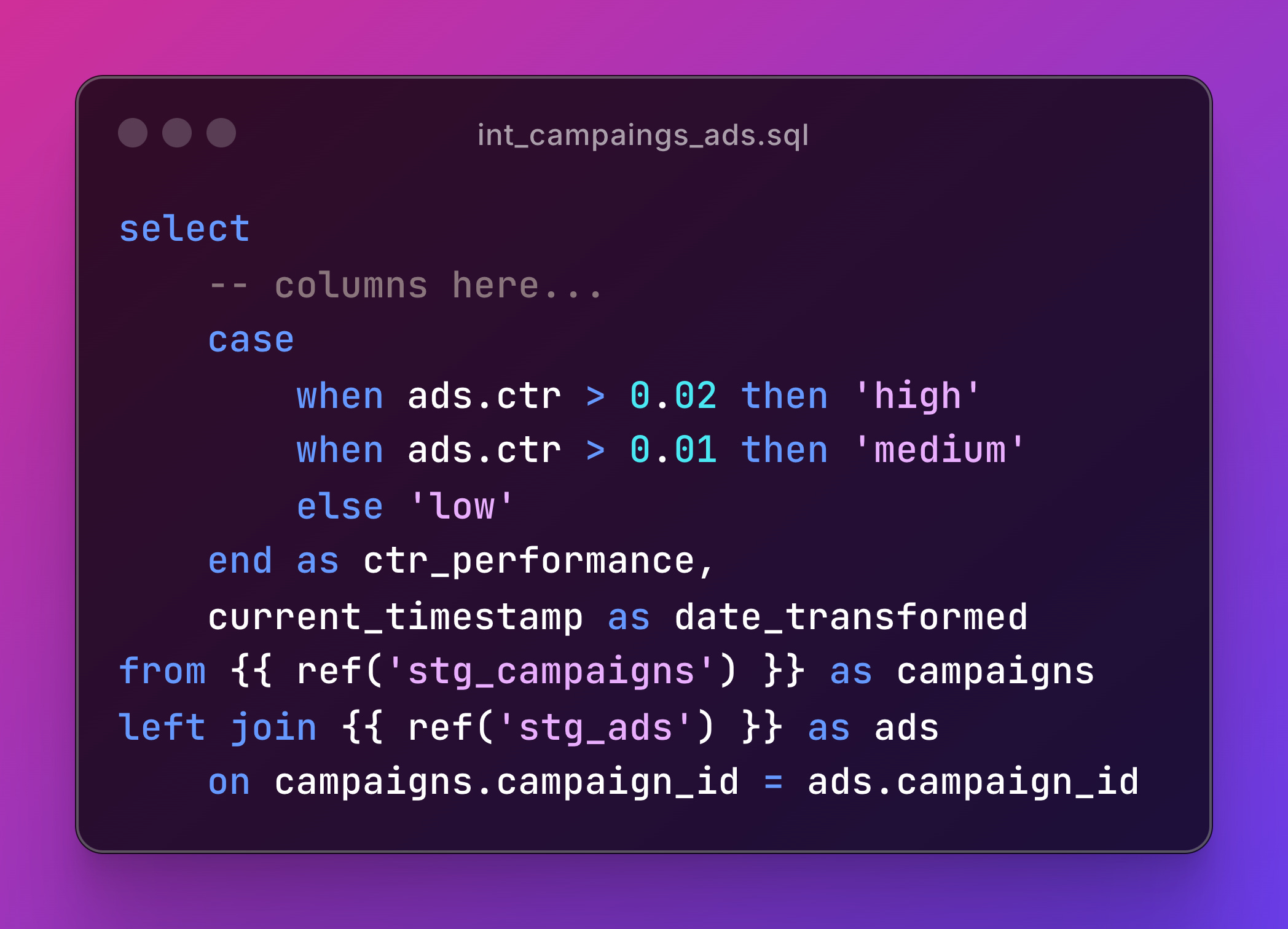
Intermediate models solve specific business problems.Each model has a clear purpose and can be tested independently.
You can see that joins are more common on this stage and logics are introduced such as ctr_performance example.
Intermediate models combine staging models with business rules. Look at int_campaign_ads.sql:
Gold Layer: Analytics Ready Assets (Marts) 🏅
This is an example of flexibility and "not following the layers strictly". You can see aggregated metrics such as total_ads or total_clicks and roas calculation which could have been handled on the intermediate layer.
Marts are your final product—tables that business users actually query. Look at campaign_performance.sql:
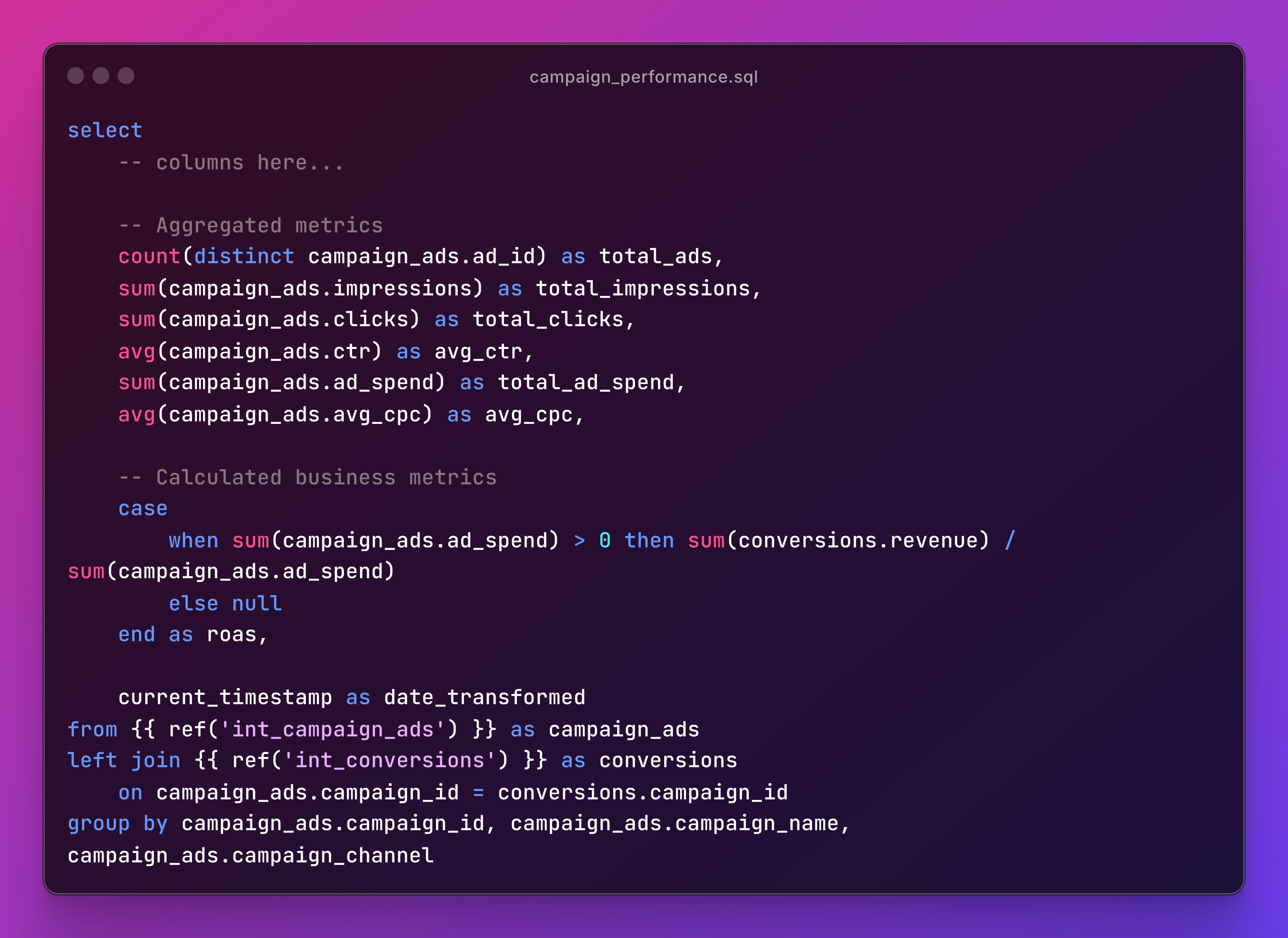
Campaign managers care about ROAS, conversion rates, and spend efficiency, this is where you get those decision drivers exposed to be used for BI workflows.
Why This Structure Actually Works
Separation of Concerns: Each layer has a clear purpose. Staging cleans, intermediate adds logic, marts serve business needs.
Testability: You can test data quality at each layer. Also you can decide if you enforced the tests as preventive contracts or as informative results.
Maintainability: it's easier to trace where to add or edit models if you have a well structured project.
Performance: Configure materialization by purpose. Decide if you need TABLE, VIEW or incremental approaches depending on the query use cases.
Bonus: dbt docs 📚
Use dbt docs to understand the whole flow of dependencies on how your models interact with each other.
Take a look!
You can also check each model specifically to see column level configuration and extra info.
Common Medallion Mistakes 😱
Not every transformation needs an intermediate model. Sometimes staging → marts is perfectly fine. Keep it flexible and don't overely if your gut and context asks for something else!

Keep staging layer simple. Complex CASE statements belong in intermediate models.
Regarding marts, if business users don't query it directly, it probably belongs in intermediate.
Poor naming conventions like tmp_stuff_v2 don't help anyone.
If you enjoyed the content, hit the like ❤️ button, share, comment, repost, and all those nice things people do when like stuff these days. Glad to know you made it to this part!

Hi, I am Alejandro Aboy. I am currently working as a Data Engineer. I started in digital marketing at 19. I gained experience in website tracking, advertising, and analytics. I also founded my agency. In 2021, I found my passion for data engineering. So, I shifted my career focus, despite lacking a CS degree. I'm now pursuing this path, leveraging my diverse experience and willingness to learn.
Love this!