
The Modern Data Trap: Solving Data Problems You Don't Have Yet
I talked with other colleages in the space, just to know that they had Fivetran, Snowflake, dbt and their top data source was a couple Google Sheets.

Hi there! Alejandro here 😊
Suscribe if you like to read about technical data & AI learnings, deep dives!
Enjoy the reading and let me know in the comments what you think about it 👨🏻💻
I worked some years ago on a company that had PostgreSQL (AWS RDS), Fivetran and Metabase.
Orchestration was handled through a 3 hour ETL process with a bunch of Python scripts and Github Actions.
The workload was typical small data, we are talking 20k rows per day on a busy day, I think it wasn’t even 50MB/day.
Back at that moment I knew way less than today, and I was not officially working on these topics, so I had almost 0 opportunities to make a difference.
It was a Modern-but-patchy data stack, but it was almost there.
Until one day where dbt cloud, Snowflake and Airflow where added to the mix to change everything forever.
3 months researching Snowflake vs Databricks, other 2 putting Airflow together.
The workflow was:
Use Airflow to call Salesforce API to fetch all its entities.
Save the outputs in S3 each day.
Create Snowflake Stages from those S3 buckets.
Run dbt daily to process those Snowflakes tables.
This were overkills or wrong use cases in so many levels. Airflow memory crashes, approaching a hybrid data lake + warehouse approach, all for 5’ daily batch processing where it was mostly dbt passing through columns without any transformations.
It was amazing, a world of possibilities… that we never got to experience at all.
Why?
There was a wide gap between business needs and infra/bills that were pilled up.
Worst part is nobody ever cared to raise a hand and say “maybe we don’t need this?”
This is the Modern Data Stack Trap I want to talk about.

🚨 Watch Out! It’s the Modern Data Trap
The data tooling industry keep convincing everyone that enterprise infrastructure is day one material.
I talked with other colleages in the space, just to know that they had Fivetran, Snowflake, dbt and their top data source was Google Sheets.
Not even Hubspot or Salesforce, not even S3 buckets. Google Sheets.
I left that mentioned job with:
A Fivetran yearly contract that had one month left to spend 90% of its contract value, otherwise it would go lost.
Paying 20k on Metabase yearly contracts for 100 licenses when only 3 people were barely checking dashboards on a weekly basis
Most of manager analysis where using Metabase manual exports to make their own graphs on Google Sheets 🤣
And this is just the tip of the iceberg, you can always see worse stuff.
From the creators of “I am a millionare inside body of a middle class person”, we got “I am Netflix infra inside the body of a small data company”
Everything has a trade off.
You pick a data warehouse like Snowflake or Databricks thinking it will remove lots of complexity to maintain it.
And that’s where the juicy part starts: you end up with the great responsibility of figuring out how to not get eaten by costs.

Or have a marvelous BigQuery bill after testing some queries:
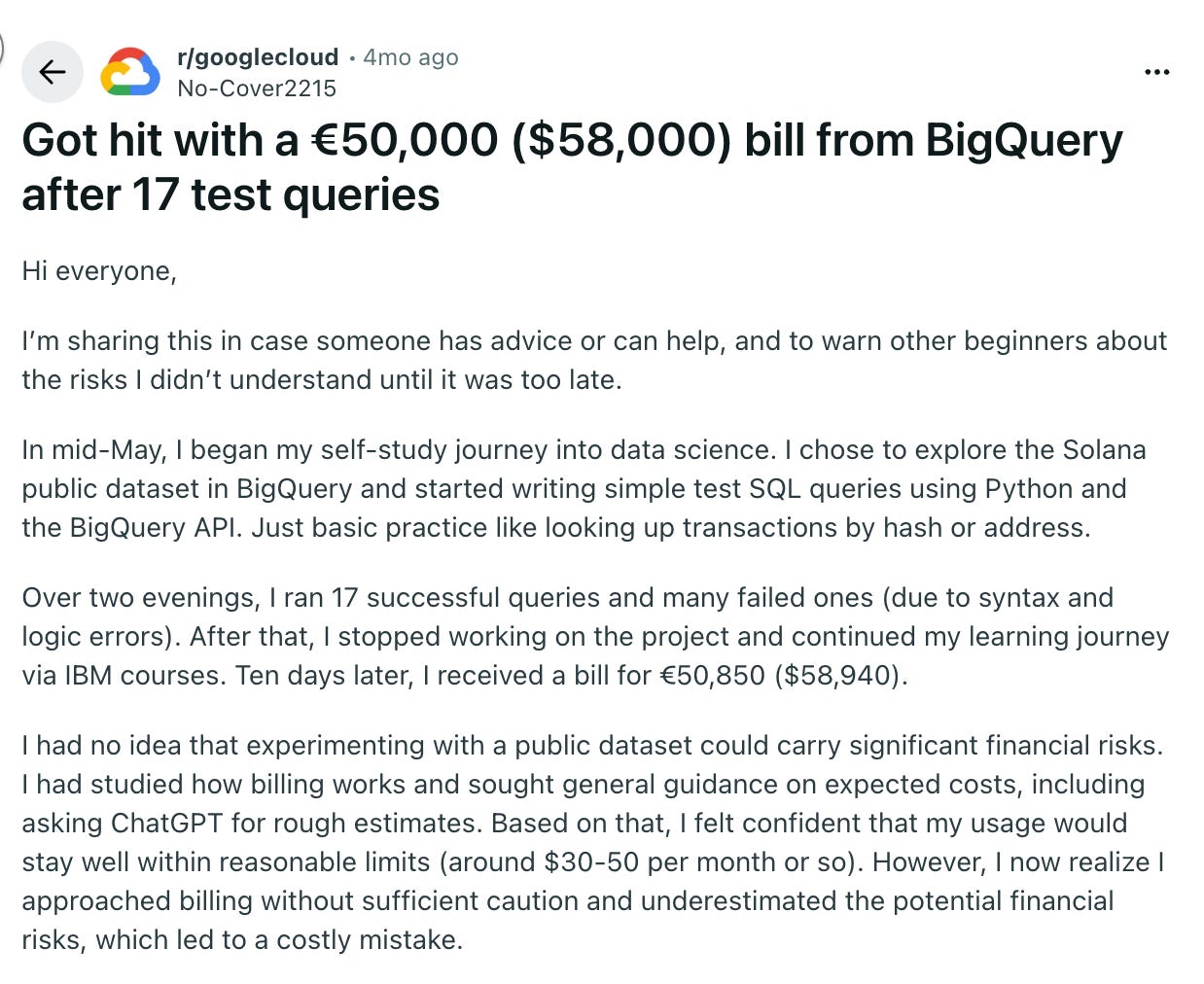
Or be held captive by Fivetran lovely price increases (this screenshot is from beginning of 2025 but they changed the pricing at the end of 2025 also 🤣)
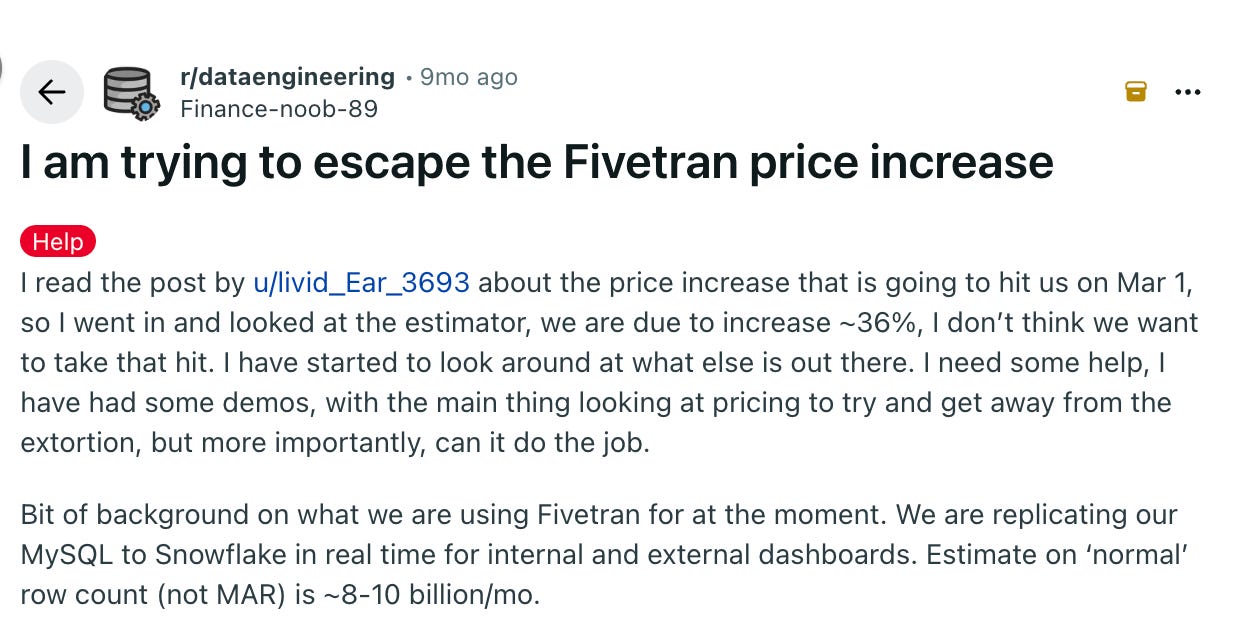
Yes, you can argue that whoever has that experience should now that you can see BigQuery costs before executing queries, or you can add LIMIT to avoid this nonsense.
You can also turn off Snowflake warehouses when unused, of setup soft-hard limits to maintain costs.
You can go to Airbyte and self host your EL processes (and deal with maintenance issues later).
Bottomline here is: beware of shiny stuff, specially when vendors are showing you how shiny it is.
Make your research, find the best option, even if you have a lot of cash to burn, the most savage investors won’t tolerate 1 year budget in one weekend.
🔧 The Unsexy Alternatives That Actually Work
Modern Data Stack as we know it (or as vendors sell it) looks like this:
AWS S3/Google Cloud Storage for Store
Fivetran/Airbyte for no-code EL (Extraction Load)
Snowflake/BigQuery/Databricks for Data Warehousing (OLAP)
Airflow for Orchestration
dbt for the “T” (Transformation) of ETL
Metabase/PowerBI/Tableau for BI & Dashboards

Now let’s take another look:
AWS S3/Google Cloud Storage for Store (Still cheap)
dlt for ETL
DuckDB for OLAP processing
GitHub Actions for Orchestration
Evidence for BI
The Pattern You Should Notice:
These tools are designed for people who want to write code to solve data problems.
They integrate with tools you already use instead of creating new silos.
You can leverage quick setups to validate business needs super fast without even jumping to spend all your budget doing POCs.
I am not again the modern data stack, I am against chasing shiny tools and killing budgets by saying your “data strategy” is setting up Snowflake.
Take a look at what Hoyt has been doing for his own private pipelines, this could easily survive in production with small data workloads without bleeding you out:

I love the “New Kids In The Blocks” Revolution.
It has been proven over and over again that you can do a LOT with almost nothing these days.
Substack authors like Daniel Beach keep showing us that you can leverage Polars or DuckDB to process huge workloads in less than a minute.

Or how Rusty Conover from Query Farm has been building DuckDB Extensions and ended up processing 50M Kafka messages in 11secs, what?

We might not have a lot of time before data people realise that we don’t need a lot to achieve the same tasks.
We can do things faster, cheaper and without a lot of overhead.
The conversation will no longer be “build or buy” no more, and it might shift to “pick the right one and make it your own”.
📝 TL;DR
Nowadays we have a lot of ways to find the best tools for the job.
Vendors, gurus and some Linkedin data evangelists don’t like to push for new use cases and will always fallback for the usual suspects.
Tools like Snowflake, BigQuery or Databricks can be amazing, overkill or a nightmare if you put them together with the wrong mindset.
The key here is to make YOUR own research and make YOUR own conclusions. And if you end up concluding Snowflake is bad because of this post, read it again 😅
If you enjoyed the content, hit the like ❤️ button, share, comment, repost, and all those nice things people do when like stuff these days. Glad to know you made it to this part!

Hi, I am Alejandro Aboy. I am currently working as a Data Engineer. I started in digital marketing at 19. I gained experience in website tracking, advertising, and analytics. I also founded my agency. In 2021, I found my passion for data engineering. So, I shifted my career focus, despite lacking a CS degree. I’m now pursuing this path, leveraging my diverse experience and willingness to learn.
It all does have a tradeoff. What I find is many of the applications described are shiny in the demo, but you do have to go in knowing they will require maintanence, and effective cost mitigation.
i agree with you, they do have a trade off, and shinier tools comes with costs, including POWERBI and TABLEAU but i don't think anything is wrong with google sheets.