
Secure LLMs for Data Engineers: Structured Outputs
In this article, we will cover ways of handling structured data for LLMs and Agentic Systems.

Hi there! Alejandro here 😊
Suscribe if you like to read about technical data & AI learnings, deep dives!
Enjoy the reading and let me know in the comments what you think about it 👨🏻💻
Most of the time, we prompt LLMs to get text as output.
But at some point, we might need something different as output: JSON or structured outputs.
Why is this relevant?
For example:
You have an AI workflow that passes a JSON payload from one step to another.
You need to add tool documentation for agents to output responses in a certain format.
The typical workflow would involve explaining in the prompt how you want the output to be. For example:
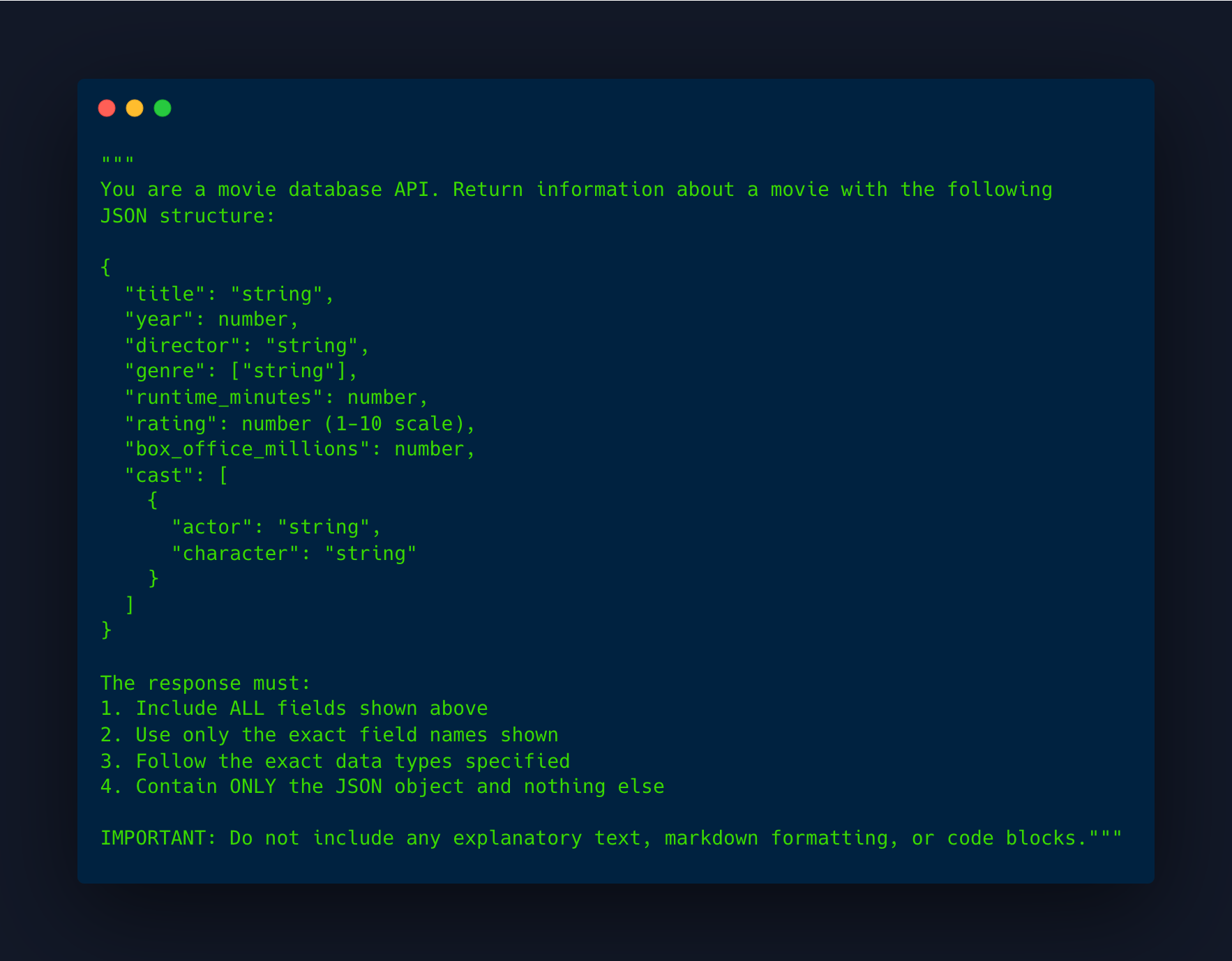
Simple, right?
Despite being a good prompting technique using the right instructions, it can still fail.

Outputs Validation
There are many combined ways of setting up an LLM to avoid JSON output failures with high fidelity.
Prompting Techniques
We just saw it. The best prompt for structured validation usually has:
Explicit fields required.
Explicit names and data types that need to be followed strictly.
Formatting: Ask only for the JSON output so it’s a valid JSON object; otherwise, it will fail when used in downstream tasks.
Other prompting techniques, such as few-shot or Chain of Thought (CoT), can really help extend this prompt to give the LLM examples of how to parse the structure and provide the right outputs.
Recommended read: Groq - Prompt Engineering for Schema Validation
Use response_format
Some other frameworks call it response_model, which stands for the very same thing.
This allows the LLM to understand what the output should be and intelligently parse the information to fit that schema.
Sometimes you might encounter differentiations between Structured Outputs and JSON mode. Basically, Structured Outputs is JSON mode with schema validation, usually done with the Pydantic package or equivalent.
This is an example from OpenAI with a vague prompt that is not asking for a JSON structure specifically, but is passing it as a function parameter (response_format) based on a Pydantic schema (CalendarEvent). See example:
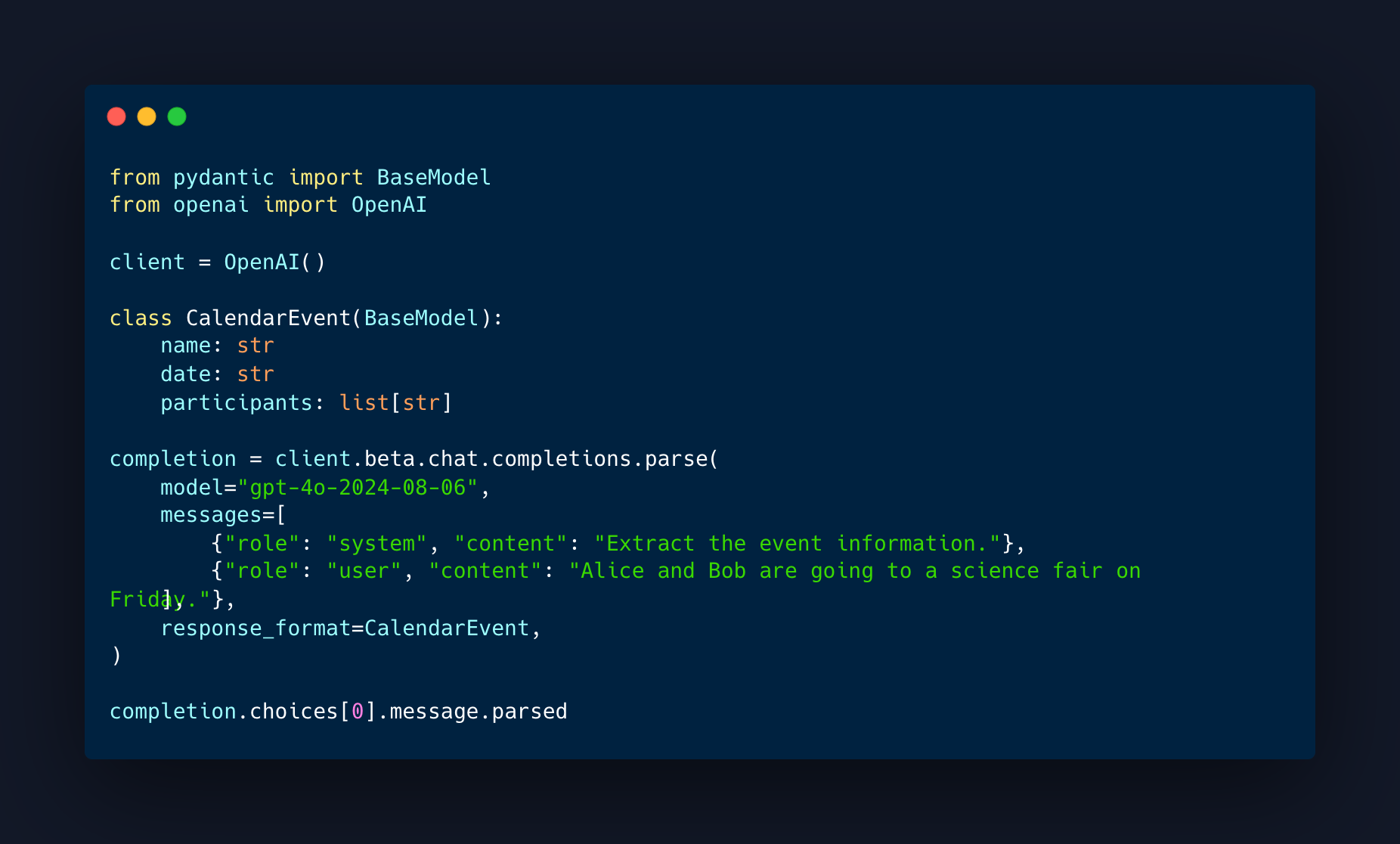
A validated schema output for this call would be:
{
"name": "Science Fair",
"date": "Friday",
"participants": [
"Alice",
"Bob"
]
}Powerful models like GPT-4.1 or Claude-Sonnet-4 are really consistent with outputs handled this way, but I have seen models like GPT-4o-mini failing randomly despite the schema being passed.
There are other methods that we can use to make sure the validated schemas have valid outputs, even when they don’t.
Instructor for Schema Validation
Instructor Library is a powerful framework specialized in structured outputs. From an implementation perspective, there’s no difference besides changing how you set up your LLM client.
Instead of this:
client = OpenAI()You would do this:
client = instructor.from_openai(OpenAI())The cool thing about Instructor is that it automatically retries failed requests with detailed error messages, ensuring your structured outputs always match your Pydantic schema.
You can even add a max_retries= parameter to your LLM API call to define how many retries you want.
Recommended read: Instructor Library
Wrapping Up
These are some good techniques to handle LLM outputs consistently for production-ready applications.
You can use some of them or find your most suitable combination of all of them.
Remember, LLMs are not deterministic; they can end up giving different outputs even with the same instructions repeated over time. With structured outputs, you fight against these odds to enable future-proof results across your AI applications.
Not all LLM models support structured outputs or packages like Instructor.
In some cases, you might need to add custom validation and retry logic in case the model is not complying with the desired output.
If you want to keep deep diving on the topic, there are other articles I can recommend:


📝 TL;DR
Outputs Validation
Prompting techniques to find the best JSON output possible
Use
response_formatto tell the LLM what is expected and how to craft it properlyUse Instructor for schema validation, retry, and error handling under the hood for production-ready applications
If you enjoyed the content, hit the like ❤️ button, share, comment, repost, and all those nice things people do when like stuff these days. Glad to know you made it to this part!

Hi, I am Alejandro Aboy. I am currently working as a Data Engineer. I started in digital marketing at 19. I gained experience in website tracking, advertising, and analytics. I also founded my agency. In 2021, I found my passion for data engineering. So, I shifted my career focus, despite lacking a CS degree. I'm now pursuing this path, leveraging my diverse experience and willingness to learn.
Maybe I'm missing something, but aren't LLMs for Data Engineers a bit overkill? Wouldn't it be more practical to focus on building experience in real-world projects?