


🗂️ Pandas vs. Polars vs. DuckDb. Who "wins"?
Pandas has been around for so long, and it has been the entrance door for many of us when we started our careers in data. But, is there any world outside Pandas?

Let’s do some quick history:
Pandas: released in January 2008
Polars: released in October 2020
DuckDB: released in July 2019
It’s been 16 years of Pandas dominance until new options have appeared on the scene. Nowadays, we can seamlessly run SQL through python and process more data without jumping into Spark or Cloud Warehouses.
I wanted to understand the difference between the 3 of them and how they perform across different file types.
I’ve created this Github Repo: 🔎 File Processing Benchmark
⚠️ Disclaimer:
All tests ran on Mac M1 Pro 16GB 2021. The presented conclusions might vary from other experiments.
Let’s get started!
🐼 Pandas
Pandas is often the first tool data analysts learn for Python. It's easy to use, versatile and helps you work with structured data easily.
It's great for:
Loading data from various sources (CSV, Excel, Databases).
Cleaning and organizing messy data.
Performing calculations and statistical analyses.
Creating simple visualizations.
This is how the syntax looks:
import pandas as pd
df = pd.read_csv('sales_data.csv')
print(df.head())
print(df.describe())
product_summary = df.groupby('product').agg({
'quantity': 'sum',
'price': ['mean', 'sum'],
'customer_id': 'nunique'
}).reset_index()
print(product_summary.sort_values(('price', 'sum'), ascending=False).head())
df['date'] = pd.to_datetime(df['date'])
daily_sales = df.groupby('date')['price'].sum().plot(figsize=(10, 5), title='Daily Sales')
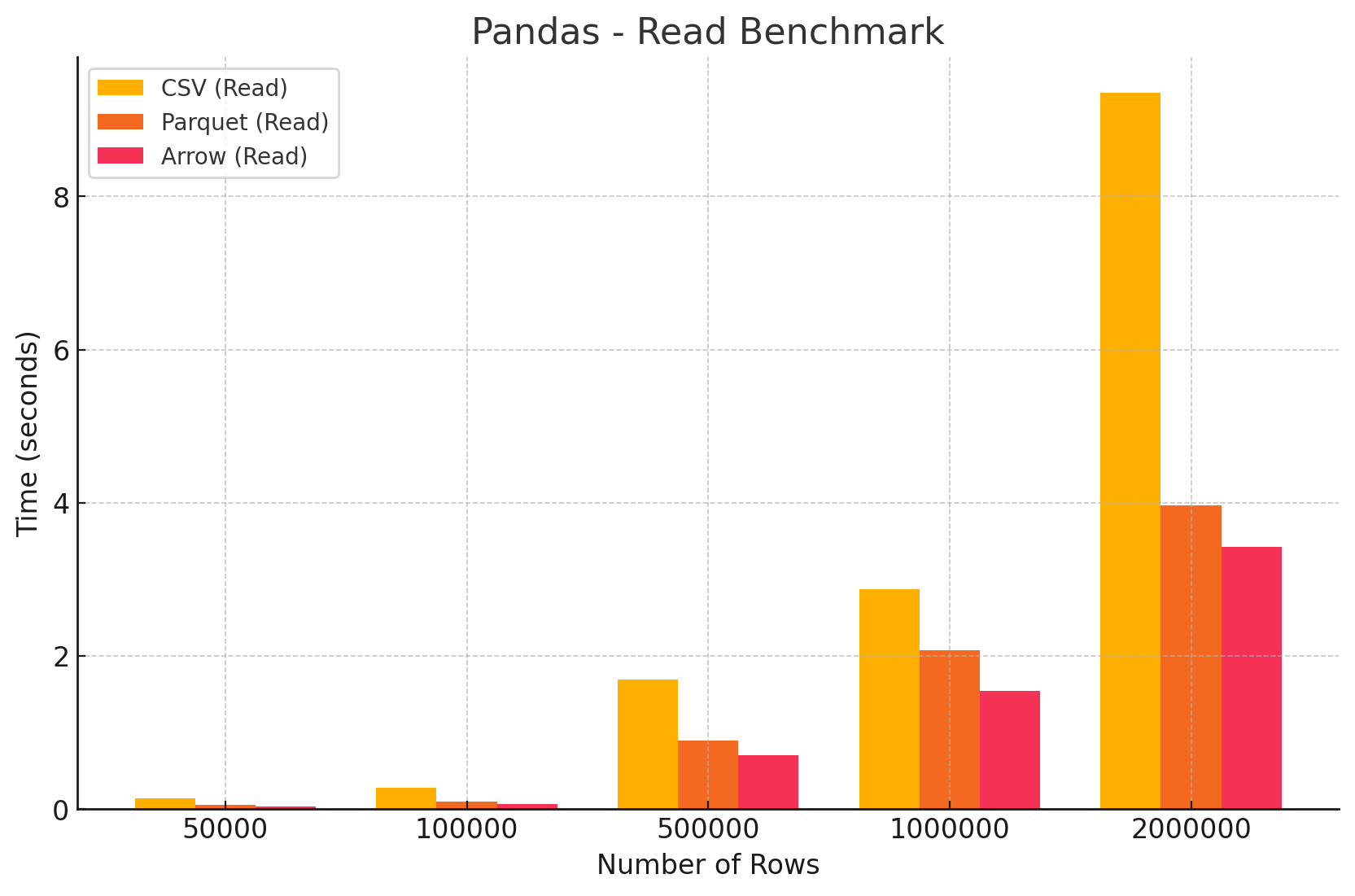
🧪 Test results:
Slowest for CSV: Pandas is the slowest for both reading and writing CSV files, especially with larger datasets.
Moderate Parquet Performance: It handles Parquet files well for small datasets. But, it slows down with larger ones.
Inconsistent with Arrow: Generally faster than CSV but slower than Parquet. Performance varies widely across different dataset sizes.
Good for Data Exploration: It suits users who value ease of use and flexibility over speed. But, it lags behind other tools for high-performance tasks, especially with large datasets.

🐻❄️ Polars
Polars is designed to be lightning-fast and memory-efficient. Think of it as a turbocharged version of Pandas.
It's great for:
Working with very large datasets that may be slow in Pandas.
Performing complex data manipulations quickly.
Handling time-series data efficiently.
This is how the syntax looks:
import polars as pl
df = pl.read_csv('sales_data.csv')
print(df.head())
print(df.describe())
product_summary = df.groupby('product').agg([
pl.col('quantity').sum().alias('total_quantity'),
pl.col('price').mean().alias('avg_price'),
(pl.col('quantity') * pl.col('price')).sum().alias('total_sales'),
pl.col('customer_id').n_unique().alias('unique_customers')
]).sort('total_sales', descending=True)
print(product_summary.head())
daily_sales = df.select(
pl.col('date').str.strptime(pl.Date, fmt='%Y-%m-%d'),
(pl.col('quantity') * pl.col('price')).alias('sales')
).groupby('date').sum()
print(daily_sales.head())🧪 Test results:
Superior CSV Performance: The fastest at reading and writing CSV files, for any dataset size.
Consistent Arrow Performance: It has a fast, consistent speed for reading and writing Arrow files.
Efficient Parquet Handling: Very fast in reading Parquet files, though write times increase more noticeably with larger datasets.
Consistent Across File Types: For read and write operations, Polars performs well on all file types, especially for small and medium datasets.
Ideal for Large-Scale Operations: Best choice for performance-critical tasks, especially when dealing with large datasets in various formats.
High dataset writing highlight: When writing bigger Parque/Arrow datasets, it was slightly outperformed by Pandas. Overhead of Polars compared to Pandas might be higher, or this could be an outlier that can be invalidated with more tests.


🦆 DuckDB
DuckDB is a super-fast in-memory database engine right inside your Python program.
It's designed to be:
Easy to set up.
Lightning-fast for data analysis tasks.
Capable of handling larger-than-memory datasets efficiently.
The best thing is that it lets you use SQL ❤️ right in your Python code. You can quickly analyze large amounts of data without learning a whole new language.
This is how the syntax looks:
import duckdb
con = duckdb.connect(database=':memory:')
con.execute("CREATE TABLE sales AS SELECT * FROM read_csv_auto('sales_data.csv')")
print(con.execute("SELECT * FROM sales LIMIT 5").df())
print(con.execute("DESCRIBE sales").df())
product_summary = con.execute("""
SELECT
product,
SUM(quantity) as total_quantity,
AVG(price) as avg_price,
SUM(quantity * price) as total_sales,
COUNT(DISTINCT customer_id) as unique_customers
FROM sales
GROUP BY product
ORDER BY total_sales DESC
LIMIT 5
""").df()
print(product_summary)🧪 Test results:
Excellent Parquet Performance: It reads Parquet files super quickly even with bigger datasets. It performs similarly to the other when writing Parquet.
Efficient CSV Performance: DuckDB excels at reading/writing CSV files for all dataset sizes. It outpaces Pandas and remains competitive with Polars with large datasets.
Inconsistent Arrow Performance: It's fast for small datasets. But, it degrades for larger ones, especially in reading.
Balanced Performance: It suits medium to large data operations and emonstrates good scalability across all file formats.


🧪 General conclusions
File Format Efficiency: Parquet and Arrow are better than CSV for larger datasets.
Scalability: Polars and DuckDB scale better than Pandas. They are better for larger datasets.
Use Case Dependence: Polars is faster. But, DuckDB is good for exploratory analysis, it can handle huge workloads!
📝 TL;DR
🐼 Pandas: use it for small explorations,& analysis. If possible, prioritze Parquet over CSV.
🦆 DuckDB: An amazing option to run EDAs for big datasets and use SQL without further effort. Use Parquet or even CSV over Arrow.
🐻❄️ Polars: it can take huge workloads easily, specially with Arrow and Parquet.
If you enjoyed the content, hit the like ❤️ button, share, comment, repost, and all those nice things people do when like stuff these days. Glad to know you made it to this part!

Hi, I am Alejandro Aboy. I am currently working as a Data Engineer. I started in digital marketing at 19. I gained experience in website tracking, advertising, and analytics. I also founded my agency. In 2021, I found my passion for data engineering. So, I shifted my career focus, despite lacking a CS degree. I'm now pursuing this path, leveraging my diverse experience and willingness to learn.