
Pytest for Data: Fixtures, Mocks, CI/CD, and Claude Code Hooks
What's the not so magical magic about pytest and what you can do to test stuff like a senior data role (even with AI).

Hi there! Alejandro here 😊
Suscribe if you like to read about technical data & AI learnings, deep dives!
Enjoy the reading and let me know in the comments what you think about it 👨🏻💻
I avoided testing and CI/CD for a long time.
I basically didn’t get why I wouldn’t just test it before merging PRs with some fake data if I had the time.
Code was tested in production because YOLO.
It started to feel more natural with tools like dbt, since setting those up in .yaml files had zero learning curve.
Every time someone mentioned pytest I would stress out by reading about fixtures, mocks, markers and other keywords that sounded zero intuitive.
I thought I needed to understand every testing pattern before I could write a single test.
But then I had to try once and for all.

🚀 What’s pytest about?
The testing world loves to overcomplicate things with fancy patterns.
But I learned that testing code goes down to:
Does my function work when I give it good data?
Does it fail gracefully when I give it bad data?
You can test the happy or not so happy path.
One thing is that your code works, but a different thing is what happens when the code does not work as expected.
The fundamentals for pytest are fixtures and mocks, which will drive your pytest strategy to verify your code integrates successfully without any issue.
Ame_data analyst wrote a nice article on data maturity that can help you understand if from a global perspective
🔧 What Are Fixtures?
A fixture is literally just a fancy name for “test ingredients.”
Instead of creating fake data over and over in each test, you make it once and reuse it everywhere:
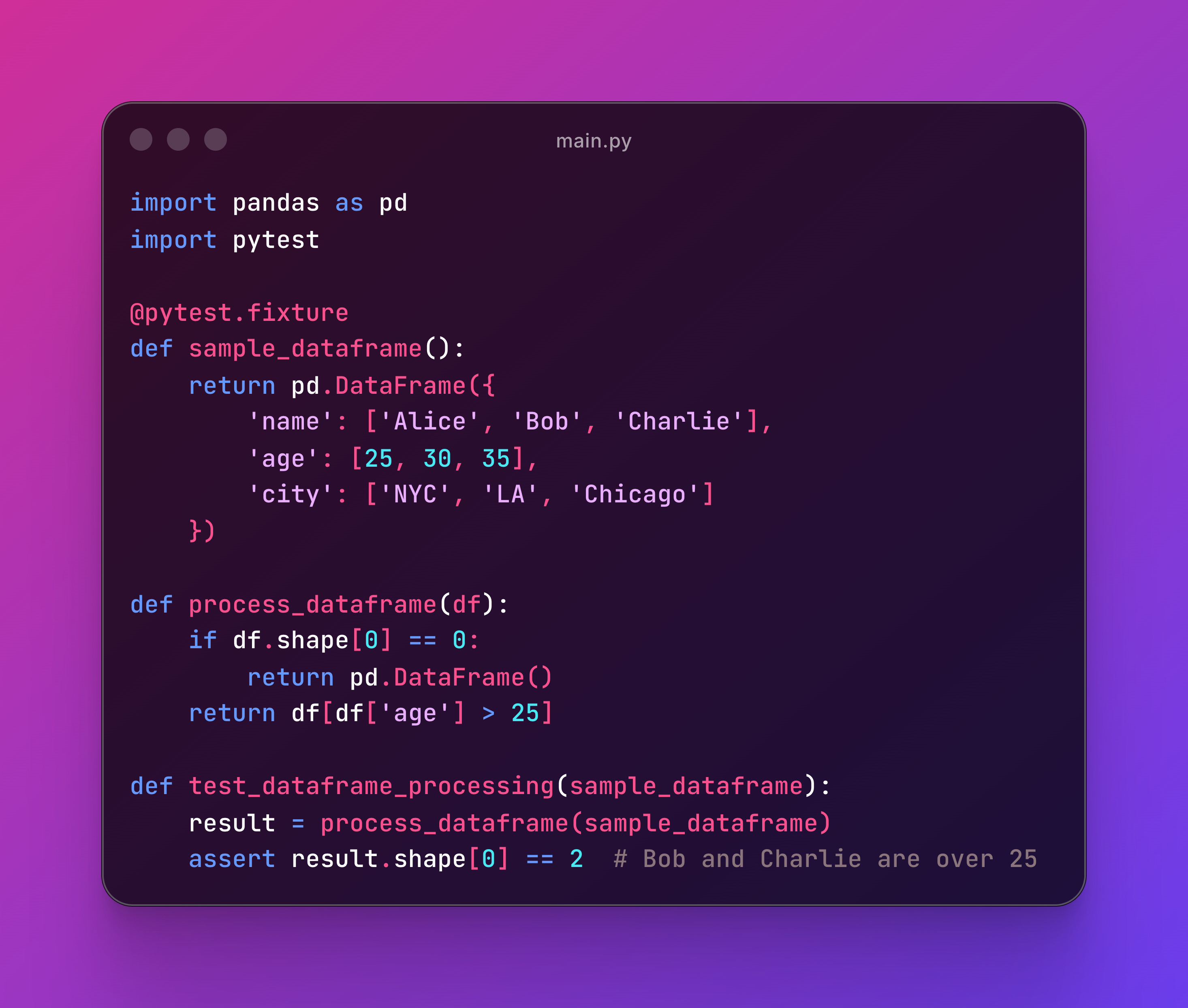
Note fixtures are static. They simulate data that you already got from somewhere else, but in data workflows, that’s more than enough.
To handle edge cases, you can customise your fixtures as much as you want to end up with solid angles to stress test your code.
Note the @pytest.fixture decorator that’s used for pytest to recorgnize that’s a fixture and not a regular function.
The assert means checking if a condition is met to conclude the test passed or not.
For example, if a dataframe is looking for rows with users that are older than 25, the shape[0] == 2 of that result will be 2 (Bob and Charlie) and the test would pass.
🎭 What Are Mocks?
A mock is like a stunt double for your code.
When you’re testing a function that calls an API to get traffic ads data, you don’t want to hit the real API every time.
That’s slow, expensive, and might fail because of network issues.
Not to mention it will overlap with other production services calling that same endpoint.
Instead, you create a fake API that always returns what you expect:
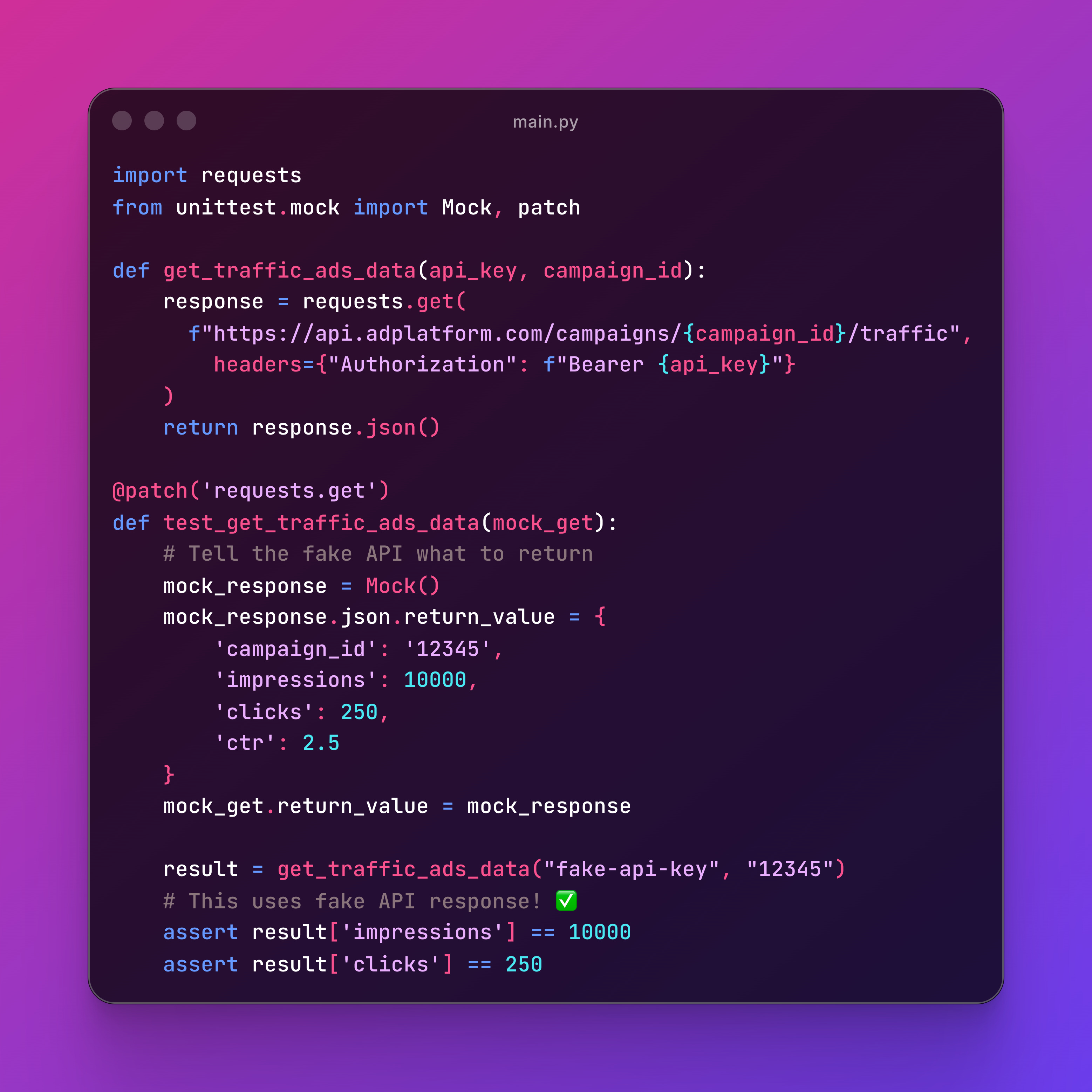
Mock() creates a fake object that you can control completely.
You tell it what to return, and it returns exactly that.
When you use your real function for the API call, it will simulate its behaviour with the mock.
@patch is the decorator that replaces real functions with your mock during the test. When the test runs, instead of calling the real requests.get, it calls your fake version.
🤔 When to Fake vs When to Use Real Stuff
There’s a saying for this:
Mock the things you don’t control (APIs, databases, file systems, etc). Test the things you do control (your business logic).
Here’s your decision tree:
Use Real Things
Testing your core business logic (data transformations, calculations)
Working with simple, fast operations (string manipulation, math)
The real thing is predictable and under your control
Use Fakes
Hitting external APIs (S3, databases, third-party services)
File system operations that could fail
Anything that takes more than 100ms to run
Network calls that might be unreliable
Note that pytest will focus on code integration first. To validate full funcionality you need a dev environment to see if real stuff will work.
You can’t pytest your way out of how an API will respond, you need to validate that last mile safely at some point.
🏗️ A Real Example: Marketing Ads Campaign JSON Validator
You have this practical example in the Pytest for Data Engineers Github Repo.
Let’s say you have a function that loads campaign data from S3 and validates it has the required fields.
This pattern is incredibly common in marketing analytics pipelines:
Ad platforms export campaign data daily → lands in S3 as JSON
Your pipeline picks it up → but you need to validate it first
Validation catches issues early → before corrupting your data warehouse
Instead of your pipeline crashing halfway through because a campaign name is null or a field name changed on the API, you validate the structure first so you can:
Send meaningful error messages to data ops team
Log exactly which campaigns failed validation
Alert stakeholders that data quality is degraded
In this case, mocking gives you control over what you want to fake, avoid overloading production of configure S3 bucket API calls or testing file uploads.
🚦Automate your tests with CI/CD
GitHub Actions are basically “run these commands when someone pushes code.”
As you can, there’s an open Pull Request that fails
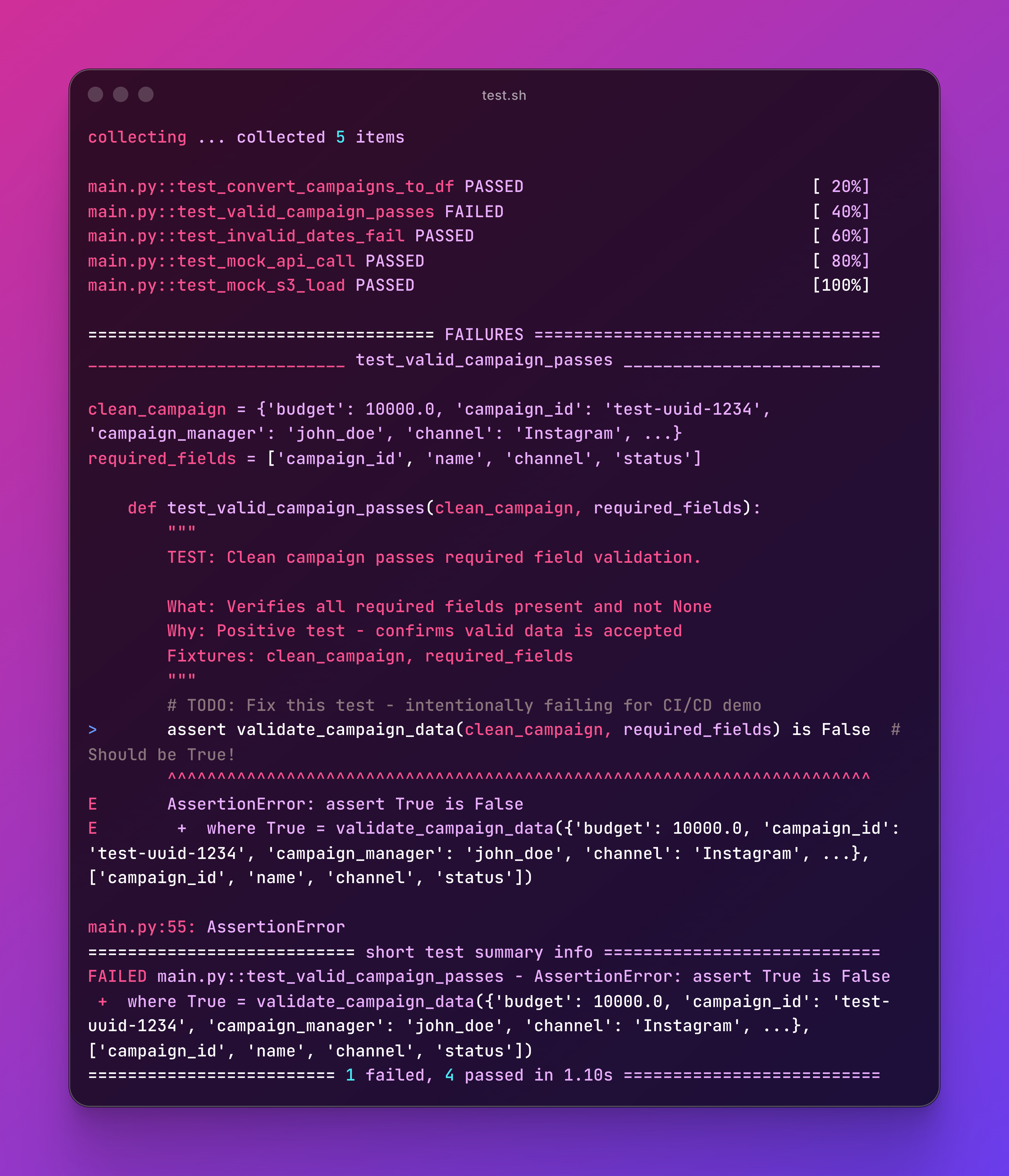
You will get notified by email if something fails.
This is amazing to prevent issues and block branches from adding problematic code.
✨ Run Pytest Using AI With Claude Code Pre Hooks
You can see in this file that Claude Code has a Hook.
What’s that?
In simple terms, it’s an action you give Claude Code to run before or after doing something else.
In this case, I have Github CI/CD, so I have to commit stuff to know if things will break or I have to run it manually every single time before commiting.
But what if Claude Code could just do it for me?
Here’s an example of what happens when I try to commit a broken test:
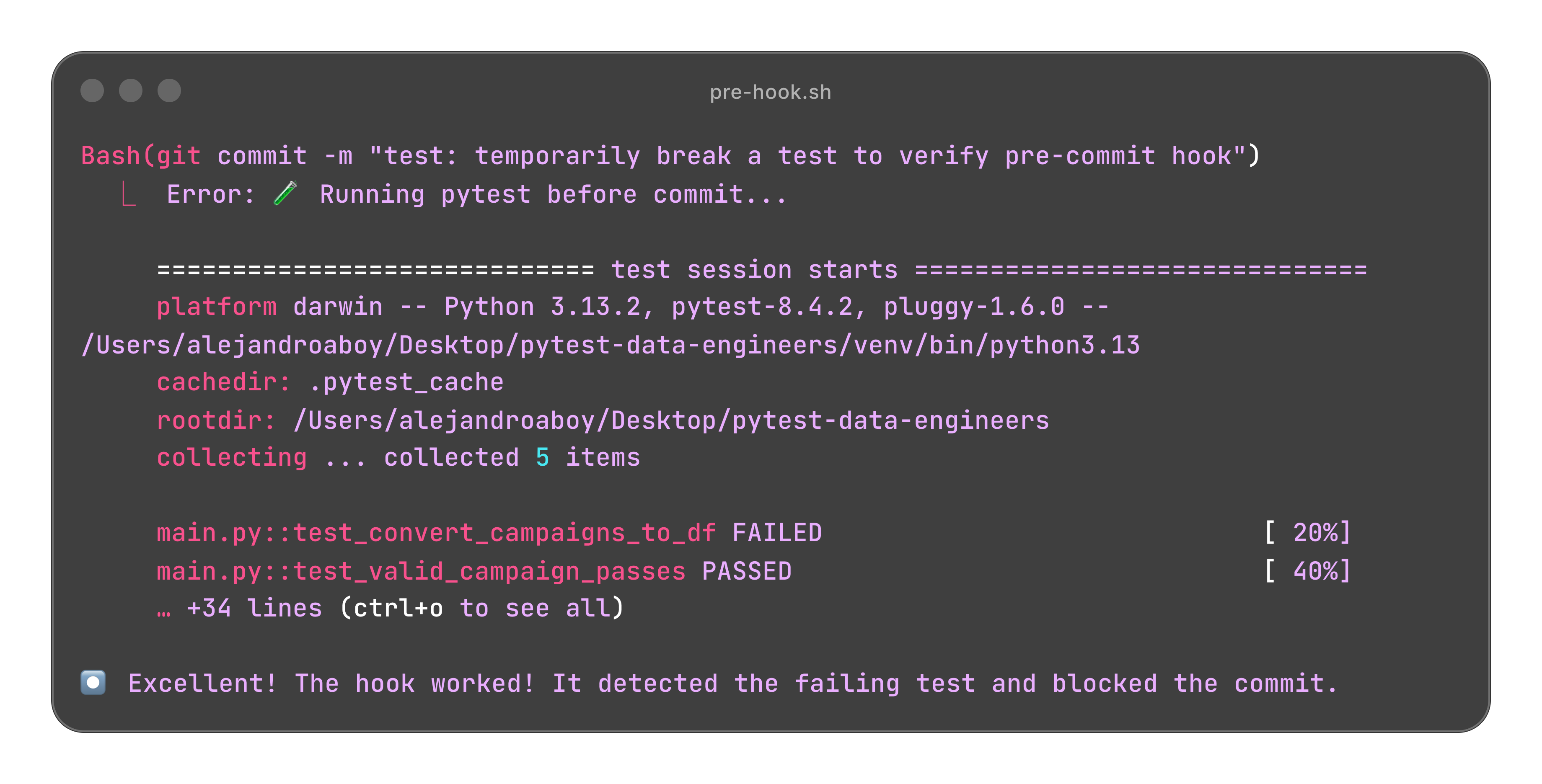
When the code is fixed and we ask Claude Code to commit the changes, it runs the pytest again.
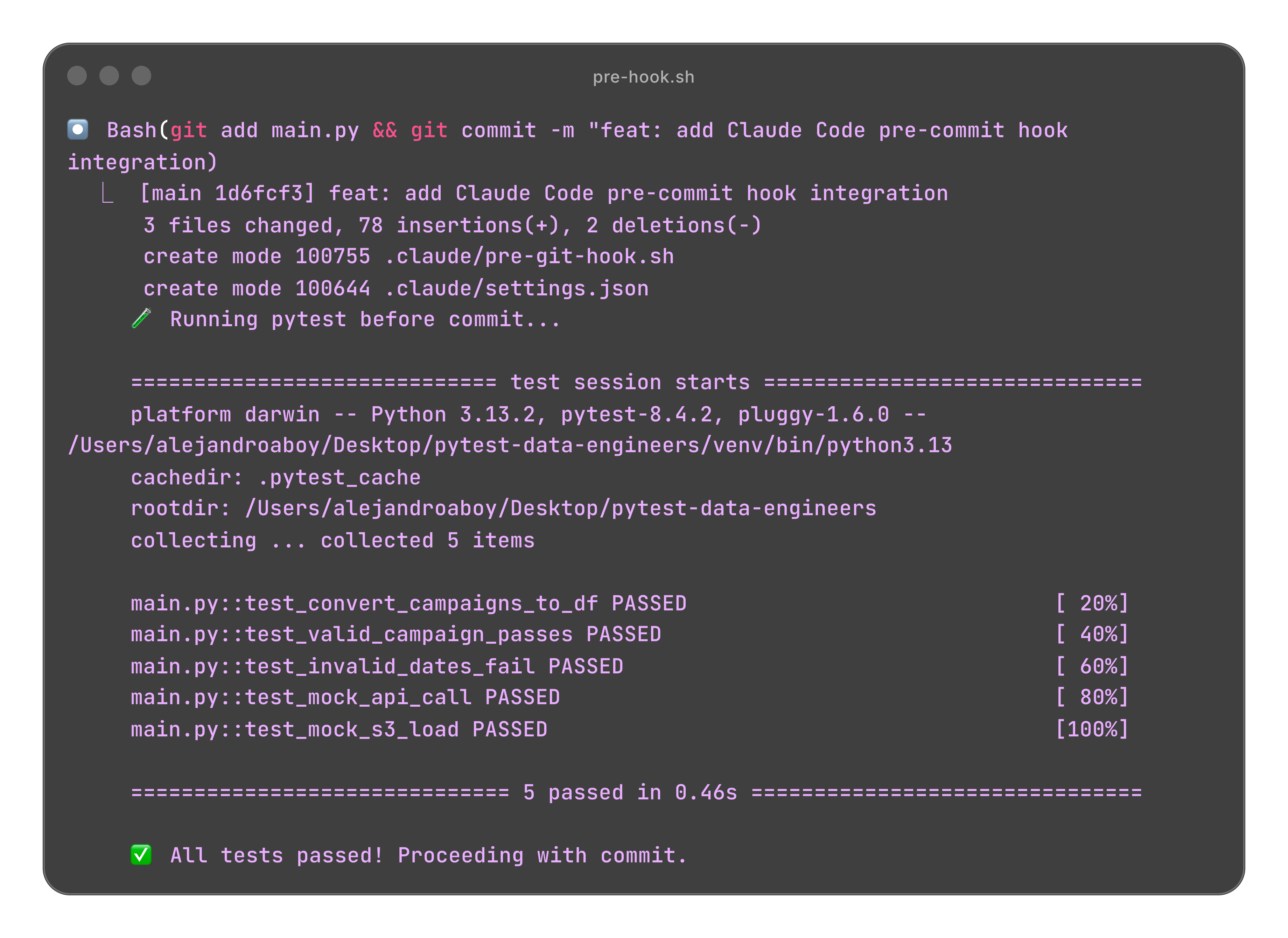
You can learn more about Claude Hooks on the docs.
You can also create Claude Sub Agents with specific instructions to create new tests when you added more code to the project, following the proect guidelines to keep consistency.
📝 TL;DR
Fixtures = Reusable test data (write once, use everywhere)
Mocks = Fake external things (S3, APIs, databases) so tests are fast and reliable
Tests = Check your logic works with good data and fails gracefully with bad data
CI/CD = Run tests automatically when code changes
Claude Code Hooks = So you don’t get to add commits that shouldn’t pass at all
You don’t need to understand everything - start simple, iterate, and add complexity only when needed
If you enjoyed the content, hit the like ❤️ button, share, comment, repost, and all those nice things people do when like stuff these days. Glad to know you made it to this part!

Hi, I am Alejandro Aboy. I am currently working as a Data Engineer. I started in digital marketing at 19. I gained experience in website tracking, advertising, and analytics. I also founded my agency. In 2021, I found my passion for data engineering. So, I shifted my career focus, despite lacking a CS degree. I’m now pursuing this path, leveraging my diverse experience and willingness to learn.
Thanks for sharing this claude code hooks, Alejandro! It looks so useful!
hey alejandro, thanks for the mention and i like how you simplified a lot of these terms. so is claude hooks like GitHub Actions? does it do the same thing for ci/cd/
also silly question: i don't have fake data, i want to want to use pytest, it may break or whatever, i've always wondered if i can get the same results if i divide the real data. so faster running time but ... don't know if that makes sense.