
Getting Started With Orchestra - Workflow Orchestration Without the Airflow Tax
How Orchestra replaces Airflow's infrastructure tax with declarative YAML and built-in observability.

Hi there! Alejandro here 😊
Subscribe if you like to read about technical data & AI learnings, deep dives!
Enjoy the reading and let me know in the comments what you think about it 👨🏻💻
📝 TL;DR
I built a multi-tenant dbt pipeline in Orchestra — webhooks, dynamic matrix execution, per-tenant schemas — and it took a fraction of the effort it would in Airflow
Orchestra’s declarative approach replaces Airflow’s Python boilerplate with YAML config and built-in integrations
Built-in observability (lineage, dbt artifacts, alerts) comes free — no extra tools or callback code
The same use case in Airflow requires dynamic DAG generation, custom operators, XCom wiring, and a separate lineage tool
Orchestra is best for teams coordinating external tools (dbt, Snowflake, Databricks) who value velocity over maximum flexibility
🎯 The Orchestration Complexity Trap
Most orchestration tutorials start with Airflow DAGs, complex graphs, and task dependencies.
You see the (recently launched) fancy UI and think “this is what real data engineering looks like.
But here’s the truth: your orchestration approach should match your project maturity, not your aspirations
But what happens when you actually need full orchestration? When Lambda’s 15-minute timeout isn’t enough, when task dependencies get complex, when you need observability across your entire data stack?
This is where most teams reach for Airflow - and where the pain begins.
I’ve worked with Airflow for years. I recognize the community behind it and also its struggle to stay relevant when other solutions start showing up and making things simpler.
We have to admit that someone has to start paving the way for others to make things better, but these days there are way better solutions that leave a lot of room for Data Engineers to implement a data vision rather than maintain pipelines that have a lot of XComs to figure out (Airflow users will know what I mean)
Think about it, with Airflow, before you can orchestrate anything, you need:
A running Airflow instance (local, EC2, Astronomer, Cloud Composer)
A metadata database (Postgres or MySQL)
Redis for Celery (if using CeleryExecutor)
Worker nodes configured and scaled
Secrets management set up
Monitoring infrastructure
Airflow Python (XCom, callbacks, Operators, etc)
You need to put together the machine, its pieces, make sure they don’t go rogue randomly and then... if you have some time to spare... focus on delivering value to the business.
I wrote about how to implement simplified and gradual orchestration setups before jumping into Airflow:
Recommended: All You Can Do Before Airflow
But other players are starting to make this even easier, so let’s talk about one of them.

What’s Orchestra?
Orchestra provides a simple workflow orchestration that allows you to put pipelines together with the mainstream Modern Data Stack tools (Databricks, Snowflake, BigQuery, dbt, etc) really quick and without all the overhead we as Data Engineers are used to.
I tested it for the first time in 2023 and it was already promising, now it’s on another level.
You have a very simple UI, straightforward documentation and if you need to go custom with Python script and such, you can add blocks for it.
Let me show you what it looks like with a real use case.
🔧 The Use Case: Multi-Tenant dbt
Use case: Run dbt models for multiple tenants, each with their own schema, triggered by webhooks when new accounts are created.
Here’s the full pipeline — a daily cron job fetches tenants from a database (1 customer = 1 schema), does some cleanup with Python, and runs the same dbt project dynamically for all of them:
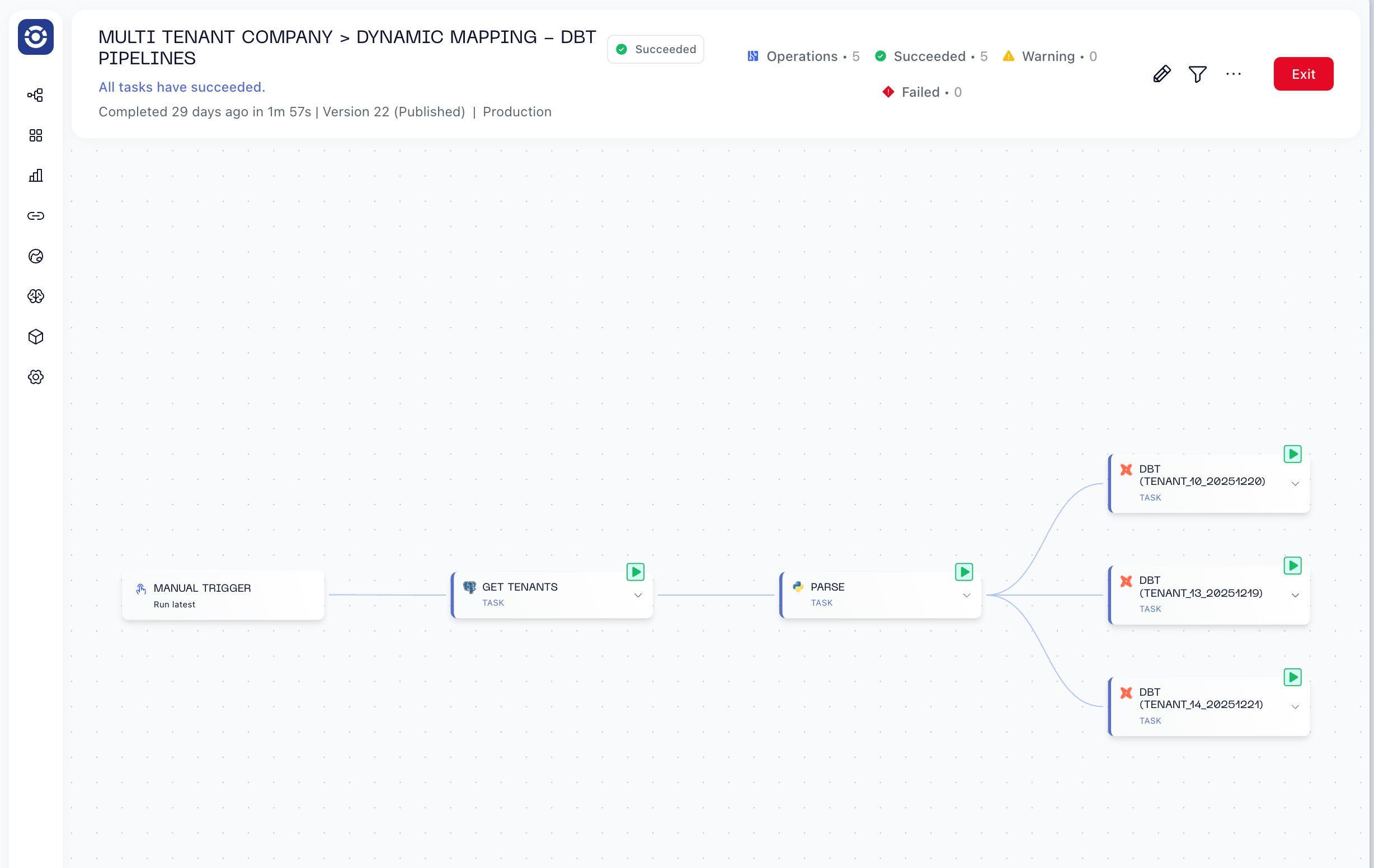
In Airflow, this would mean dynamic DAG generation, XCom wiring across tasks, and a lot of Python files handling dependencies. In Orchestra, it’s declarative. Let’s walk through it.
Webhook Triggers
Orchestra makes webhooks trivial. You get a URL, configure the payload mapping, and you’re done.
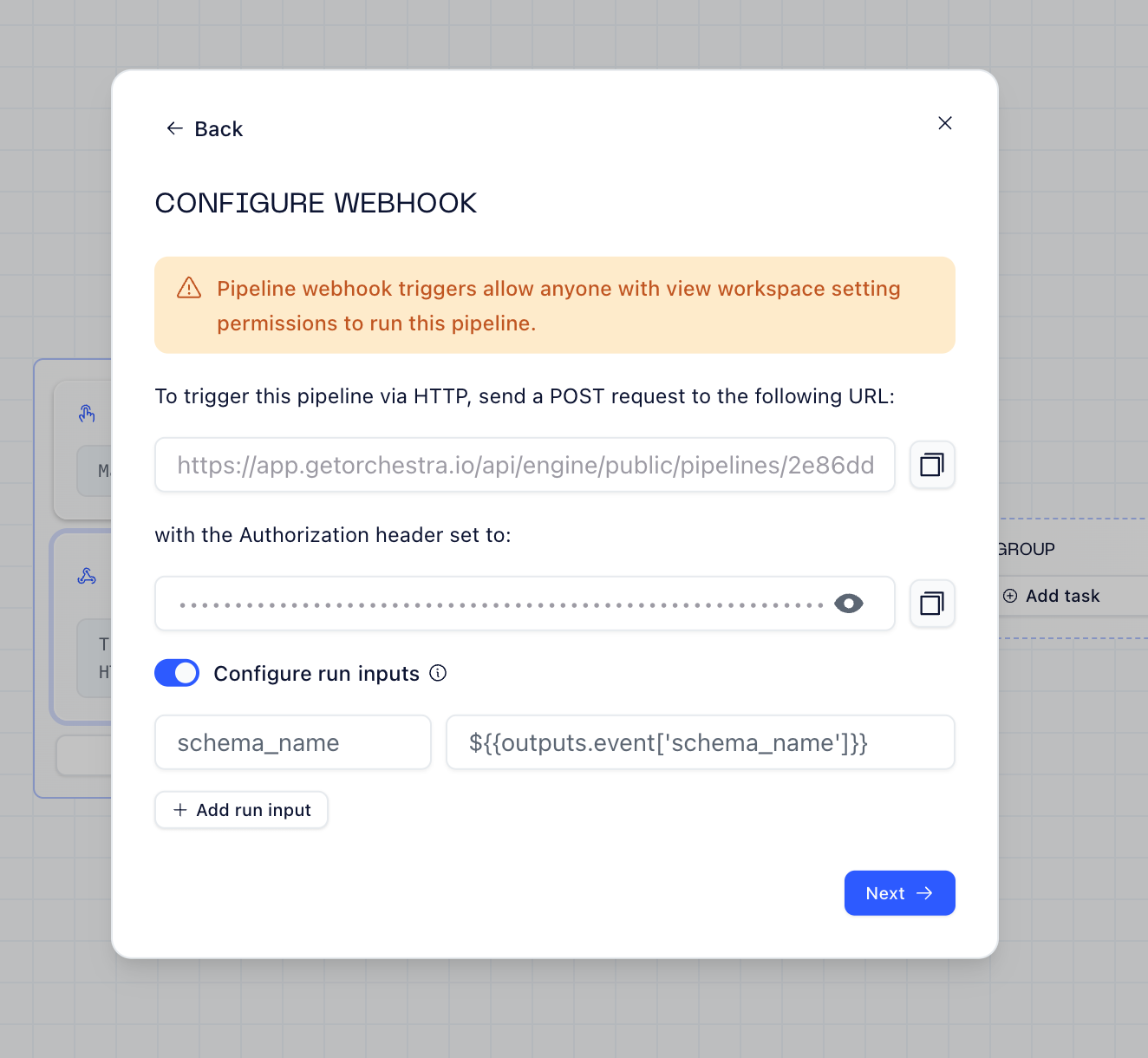
When a new tenant signs up in the backend, it hits the webhook with the schema name and Orchestra kicks off the pipeline. Here’s the Python side:
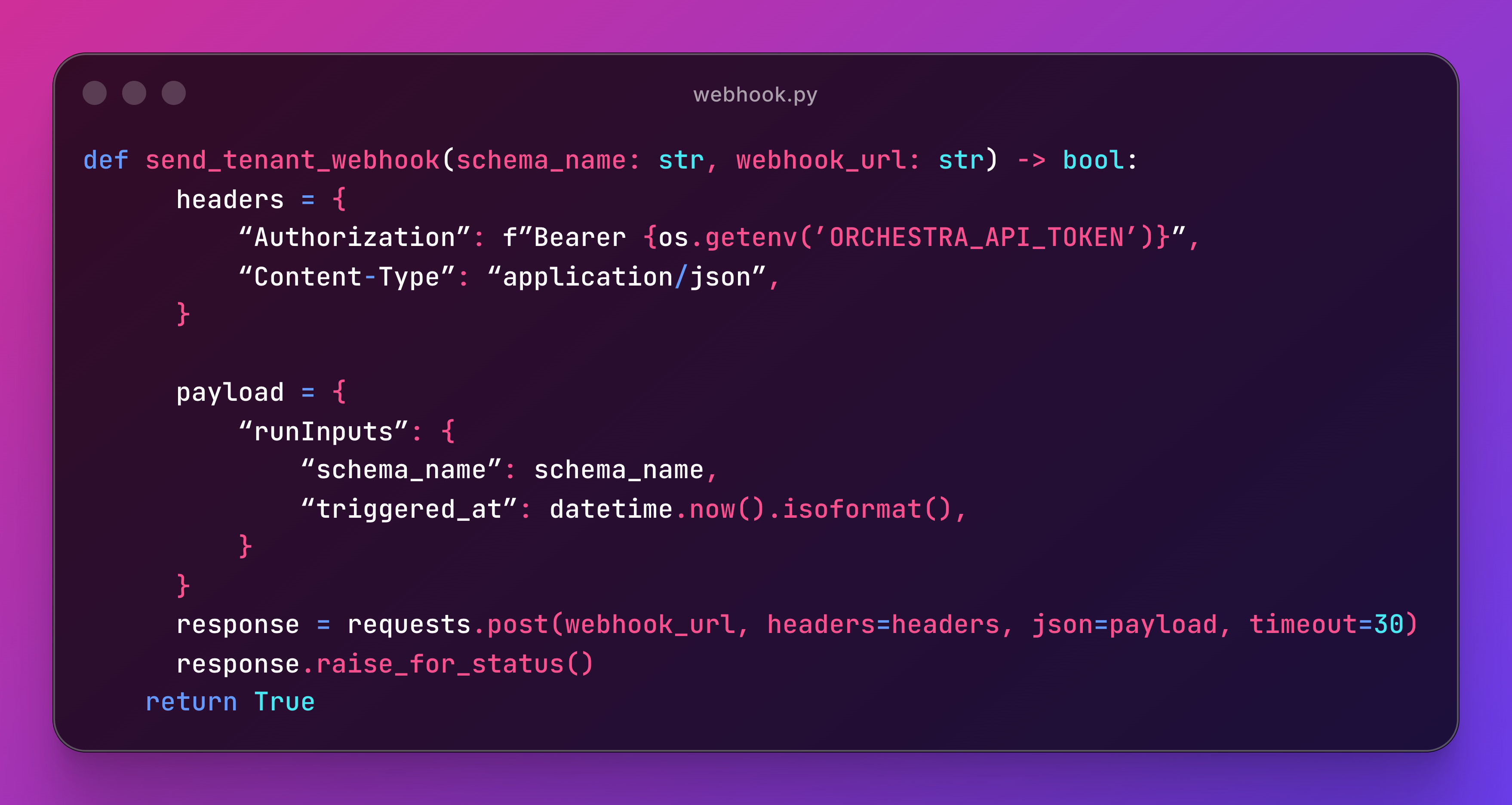
A simple POST with `runInputs` — Orchestra catches it, extracts the schema name, and kicks off the pipeline.
Resources: Webhook Triggers
Dynamic Matrix Execution
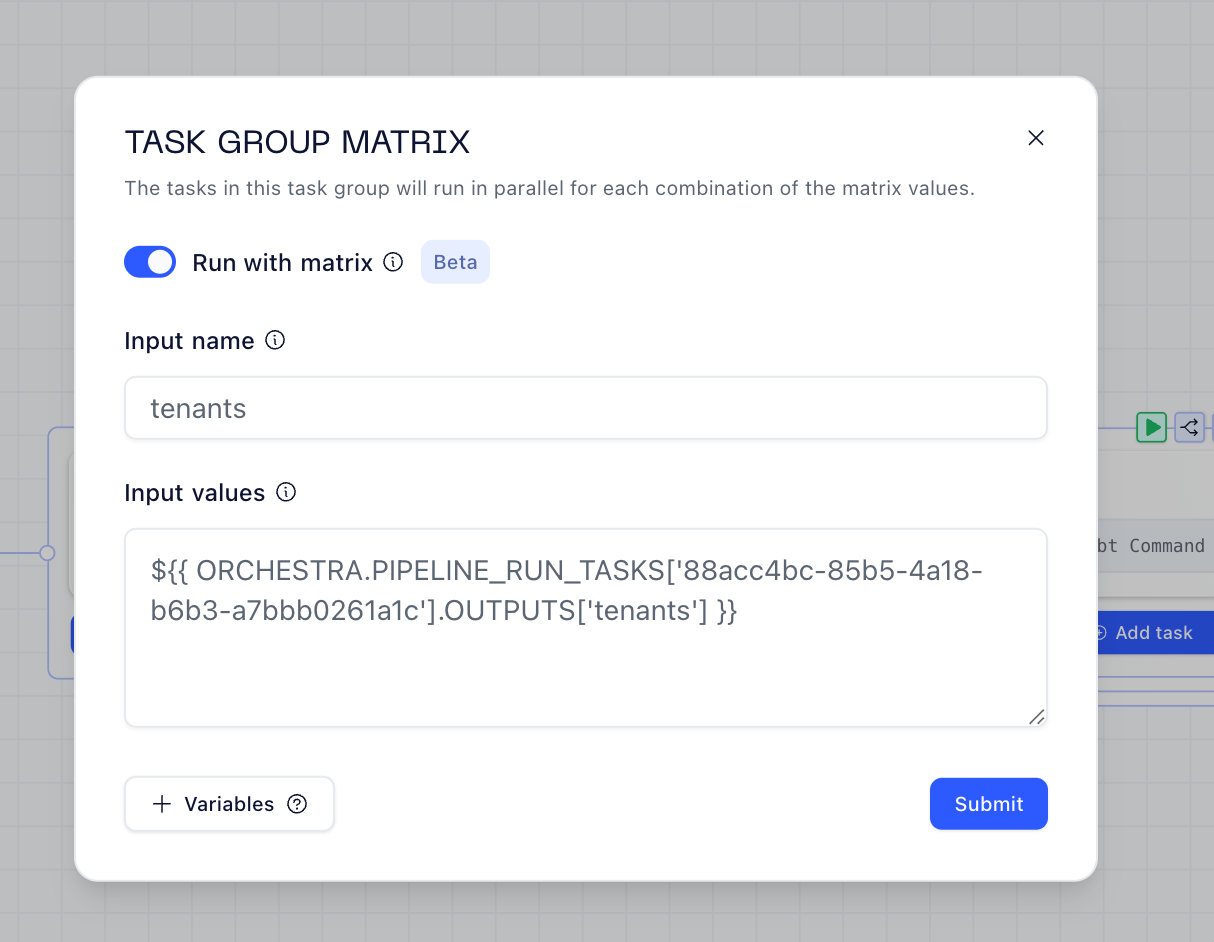
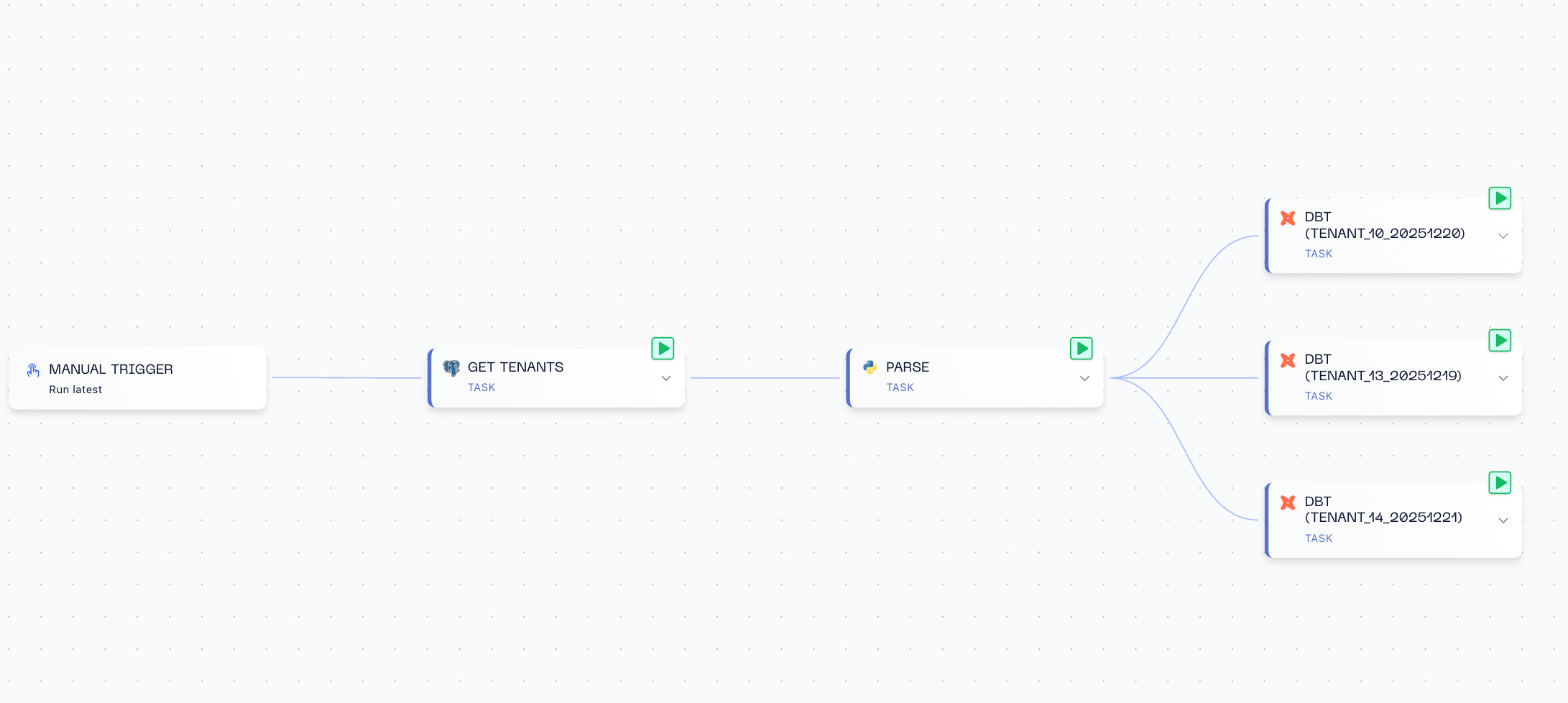
The real magic is the matrix mapping. Instead of hardcoding tenant schemas or generating DAGs dynamically, I use Orchestra’s built-in matrix feature.
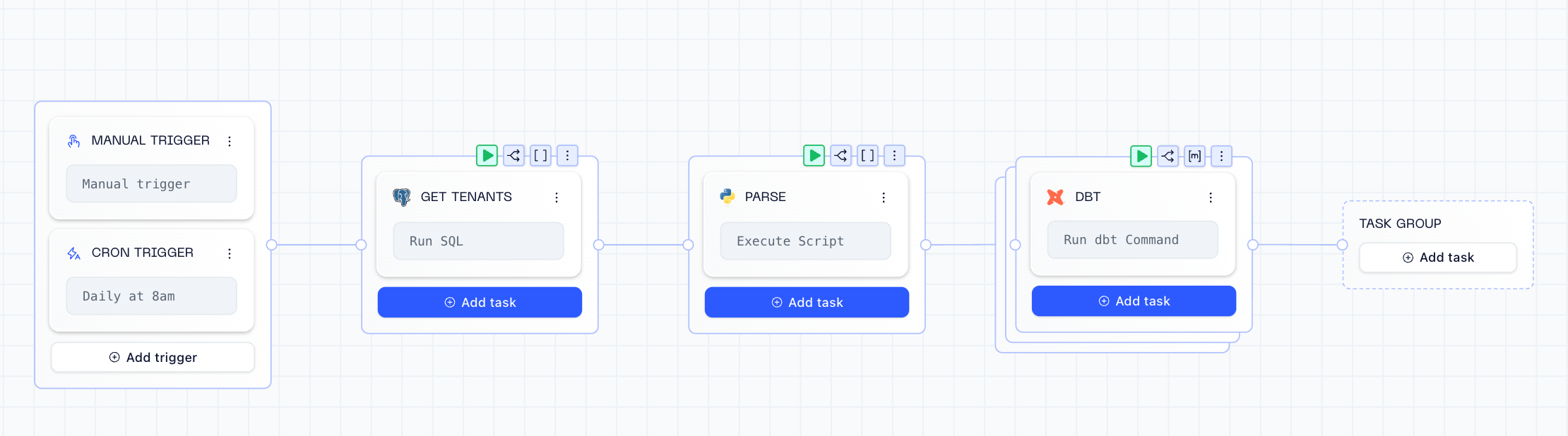
First, a SQL task queries which tenants need processing:
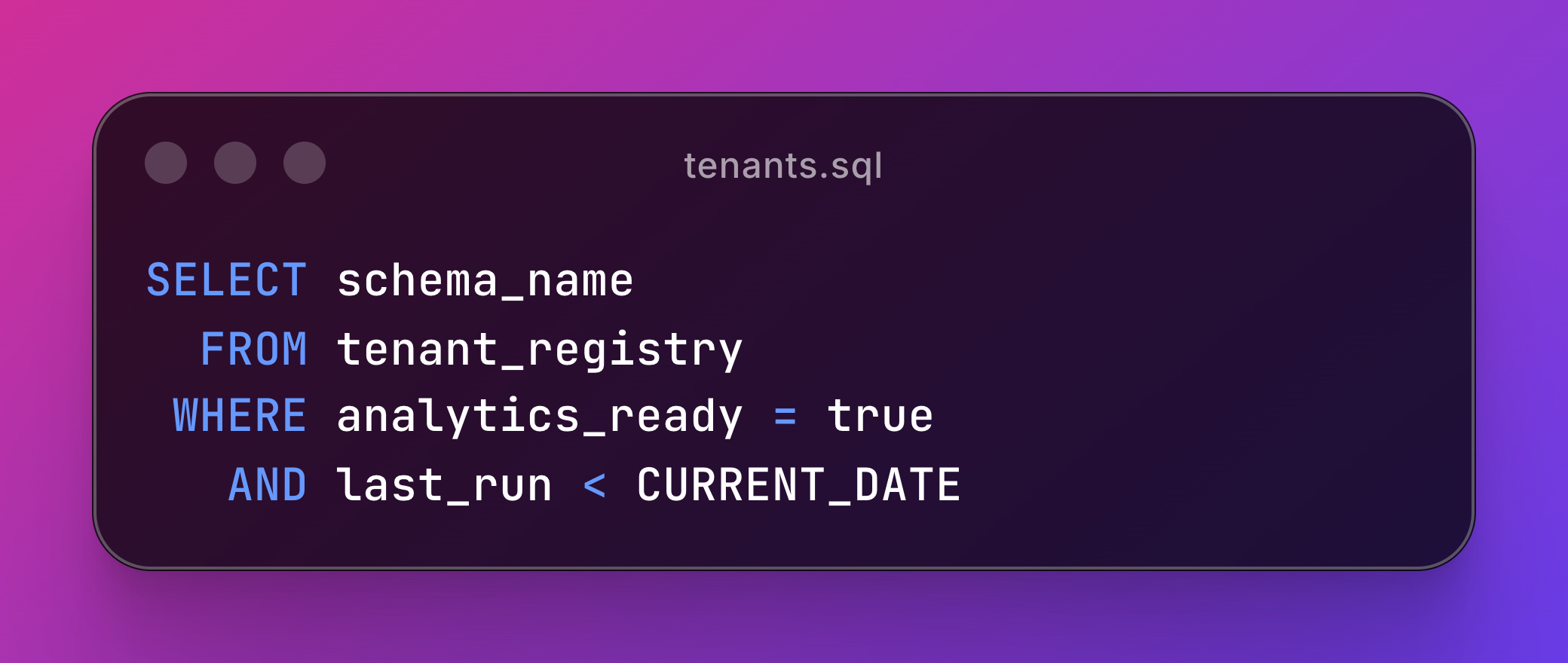
After some python parsing to format the output, Orchestra runs the dbt task in parallel for each schema returned:
The dbt configuration accepts the schema as a variable, and since this is a multi tenant approach, we use target-path:
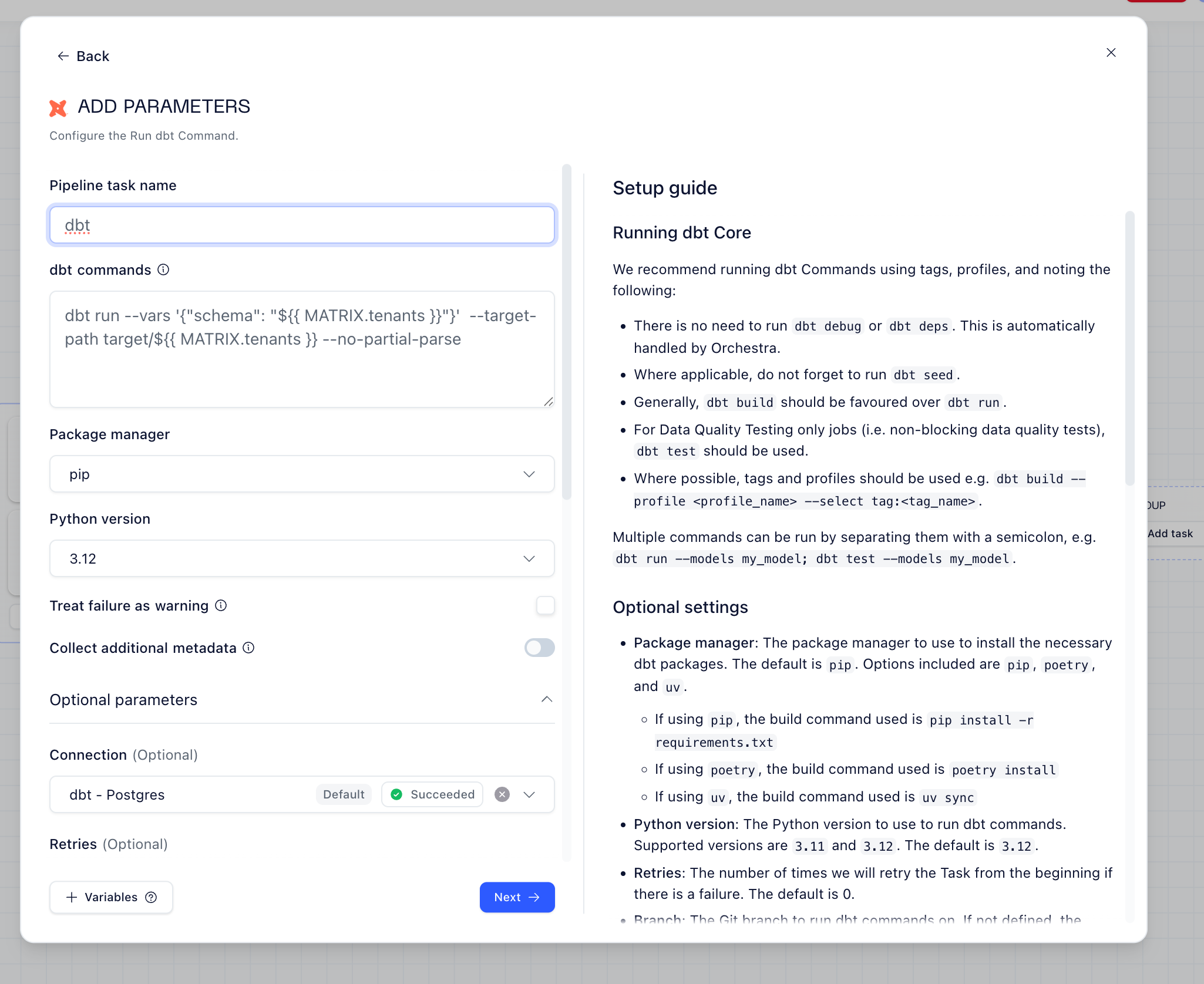
In Airflow, this pattern requires:
Dynamic DAG generation with Jinja
Custom operators for parallelization
Manual task mapping logic
Careful memory management for large tenant lists
Orchestra handles it declaratively.
Resources: Matrix Execution
Inline Python for Custom Logic
Sometimes you need to do more than call APIs. Orchestra supports inline Python directly in the UI:
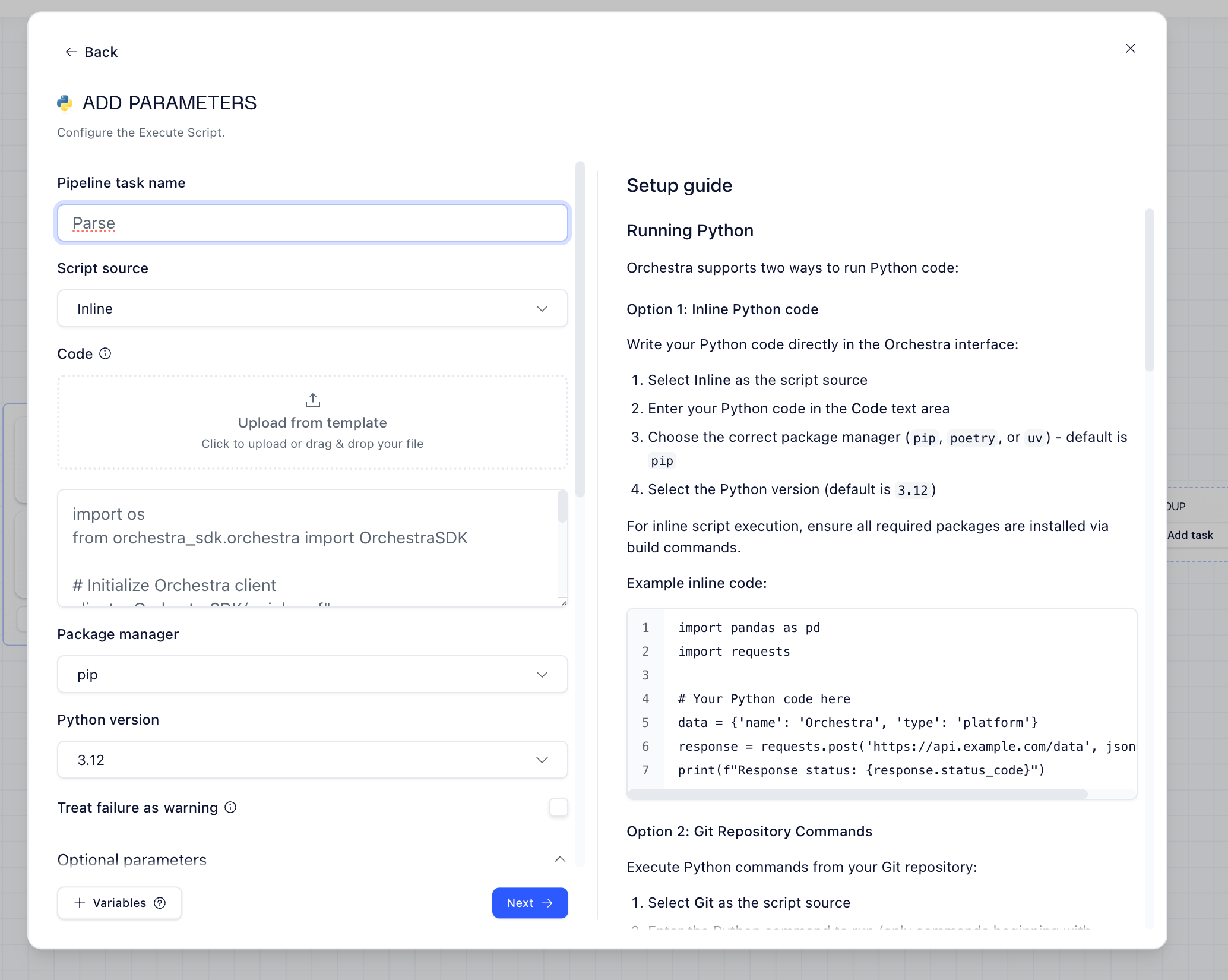
No need to package Python scripts, manage dependencies, or deploy containers. Write it inline, Orchestra runs it.
Resources: Python Tasks
Observability & Lineage
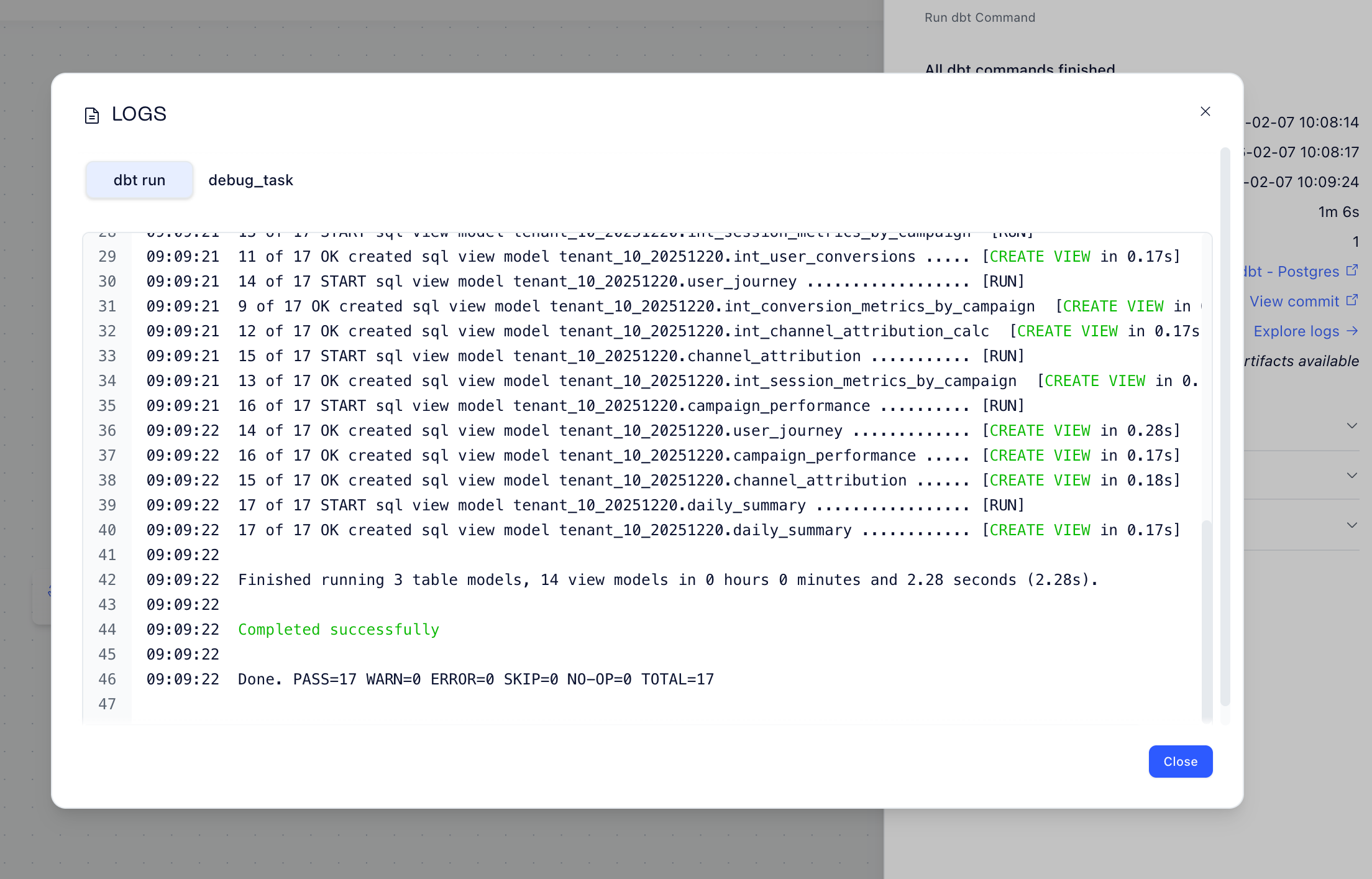
I ran my multi-tenant pipeline — here’s what I get for free, without any extra configuration:
dbt Artifacts: Full logs, model timings, and test results right in the UI:
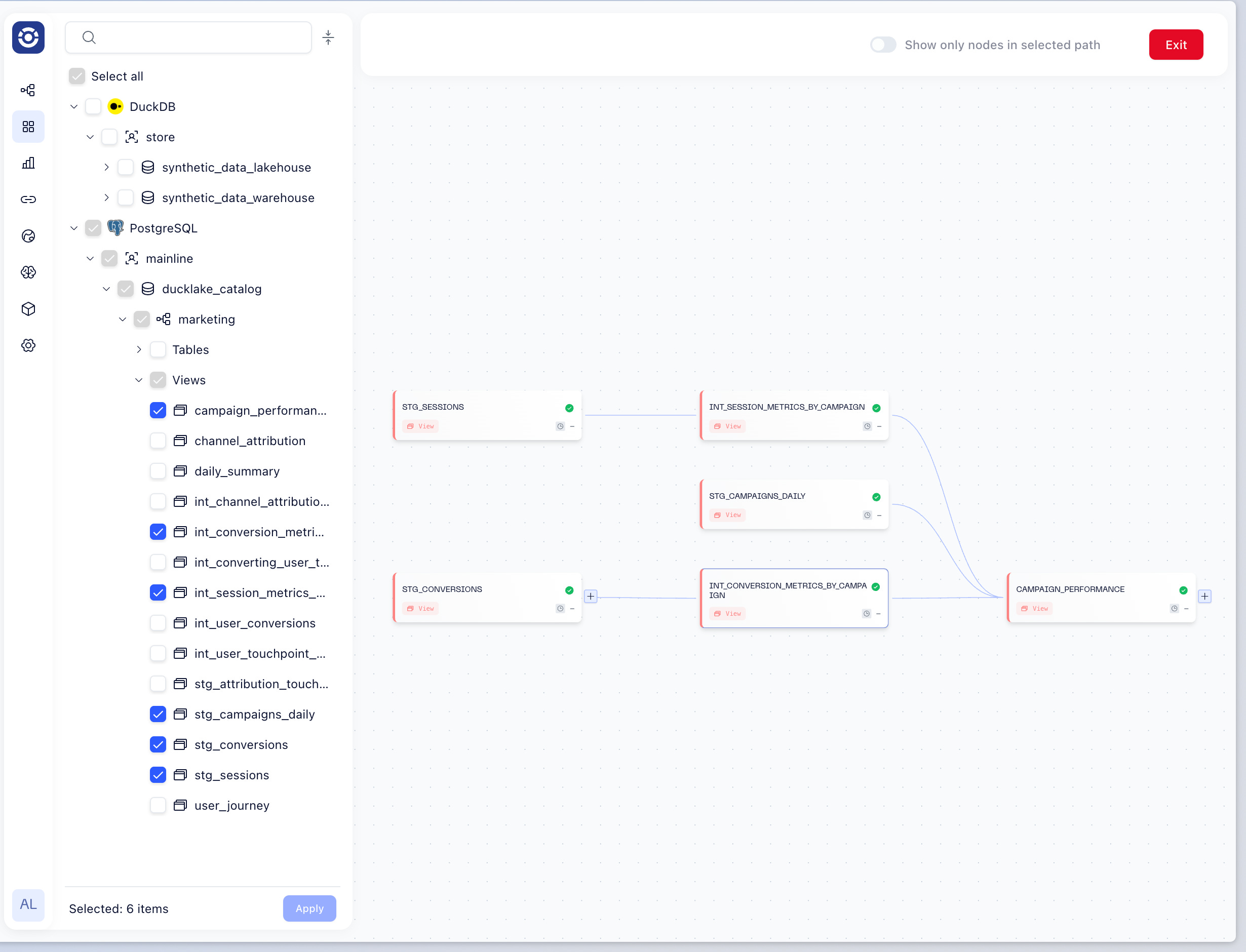
Data Assets & Lineage: The complete dependency graph from staging to marts, with dependencies automatically mapped. Click any node to see last run status, data quality test results, query history, and downstream dependencies:
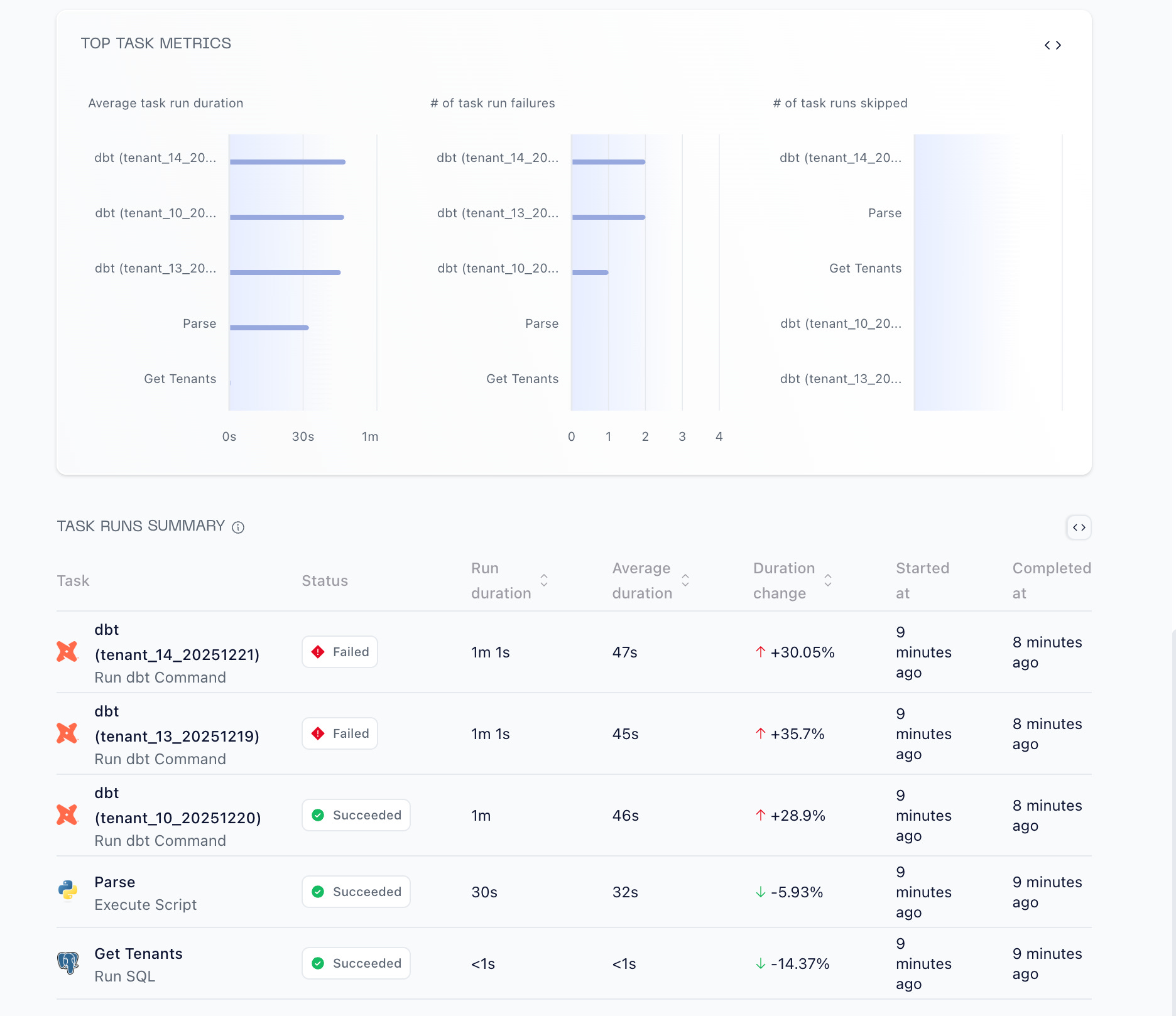
You also have embedded Analytics to see how all your pipelines are performing:
Resources: Observability - Lineage - Artifacts
Quick Alerting Setup
Use Jinja Templates to put alerts in place and don’t bitch about callbacks and all that stuff, it’s super fast to spin up for Email or Slack.
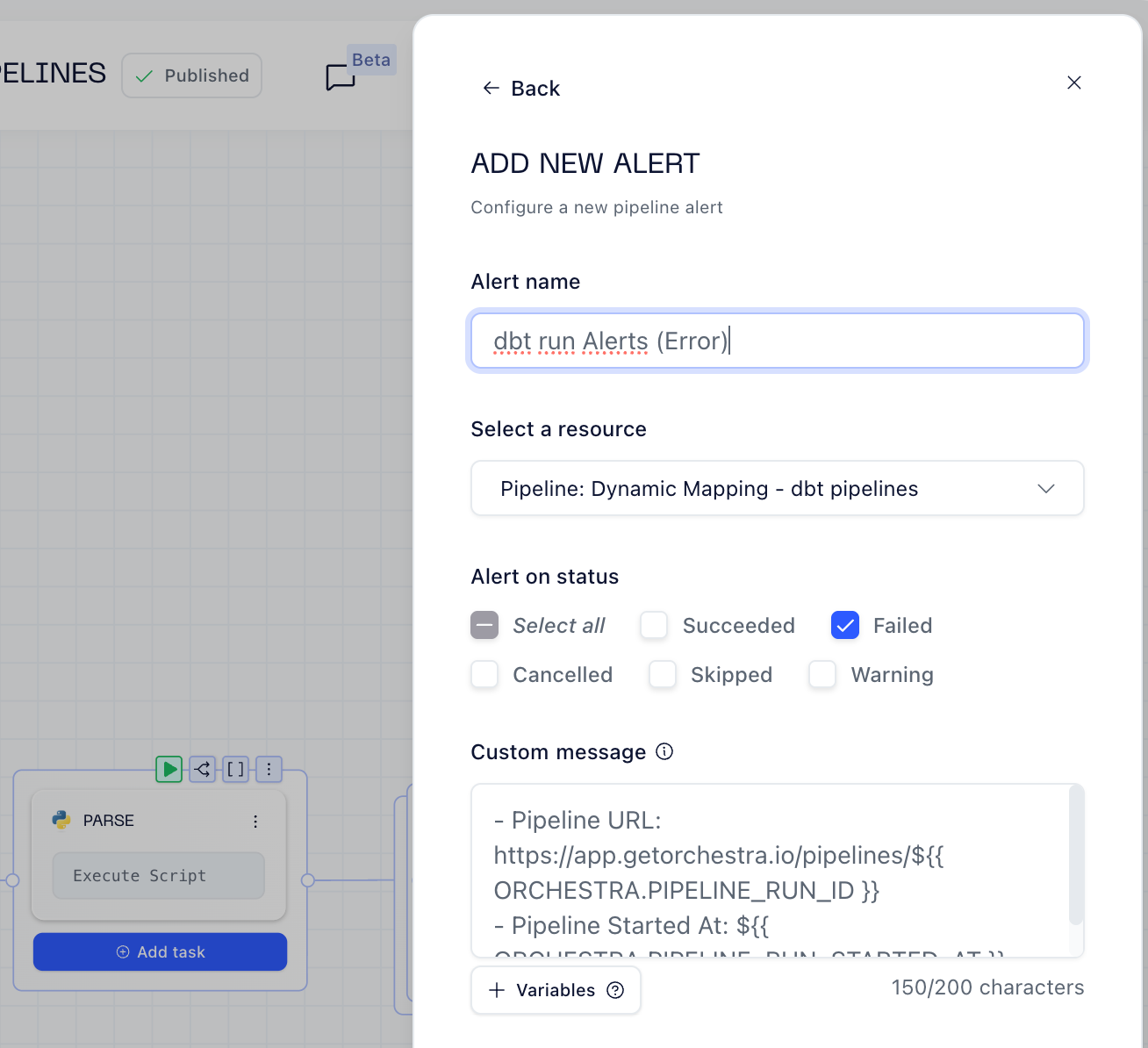
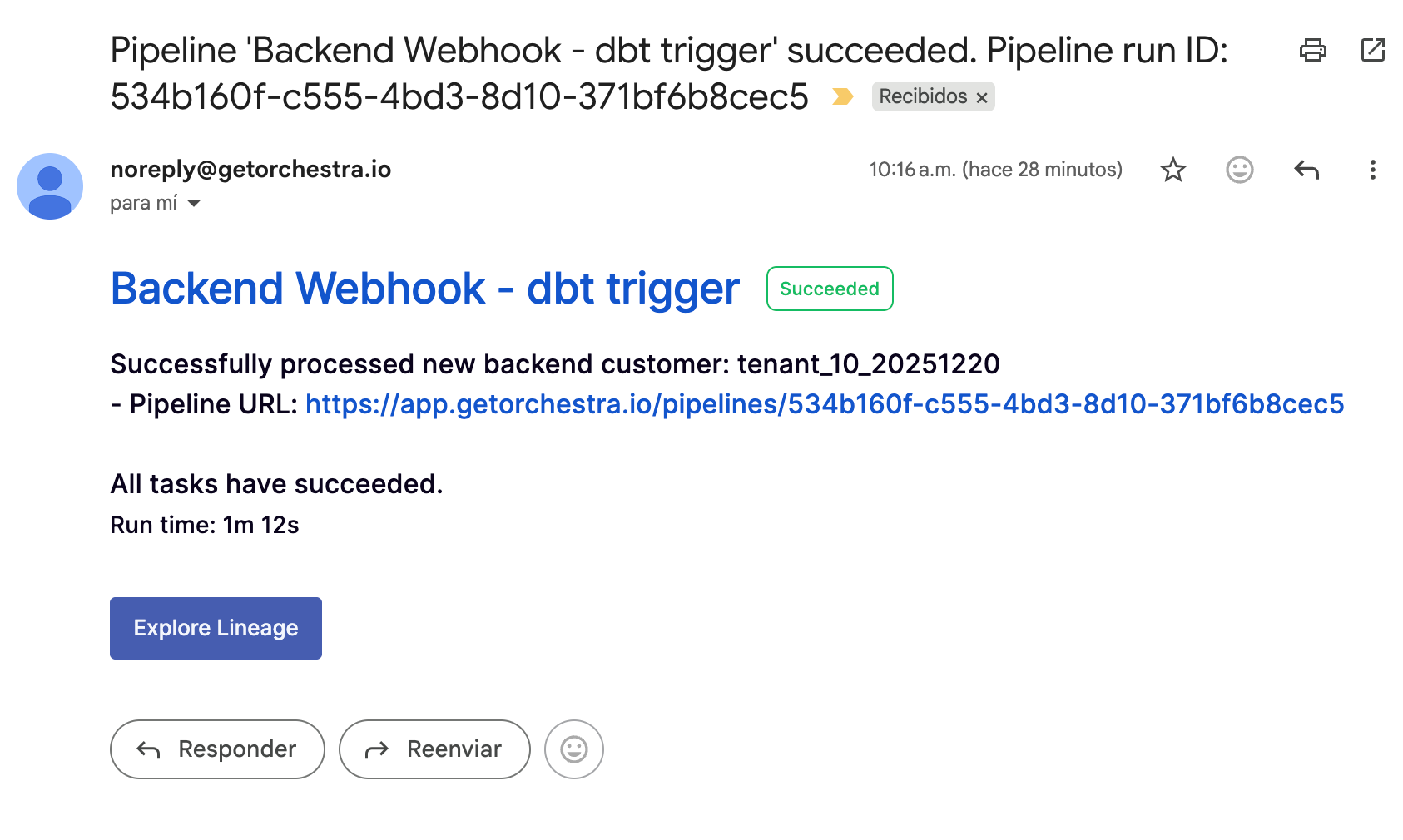
Resources: Alerting
💡 The Path Towards Declarative YAML Pipelines
Orchestra’s GitBridge enables bi-directional sync — pull pipeline YAMLs locally, edit them in your IDE, and push changes back through CLI.
Orchestra uses versioned YAML files. So it’s quite easy for you to go through versions to understand pipeline development evolution.
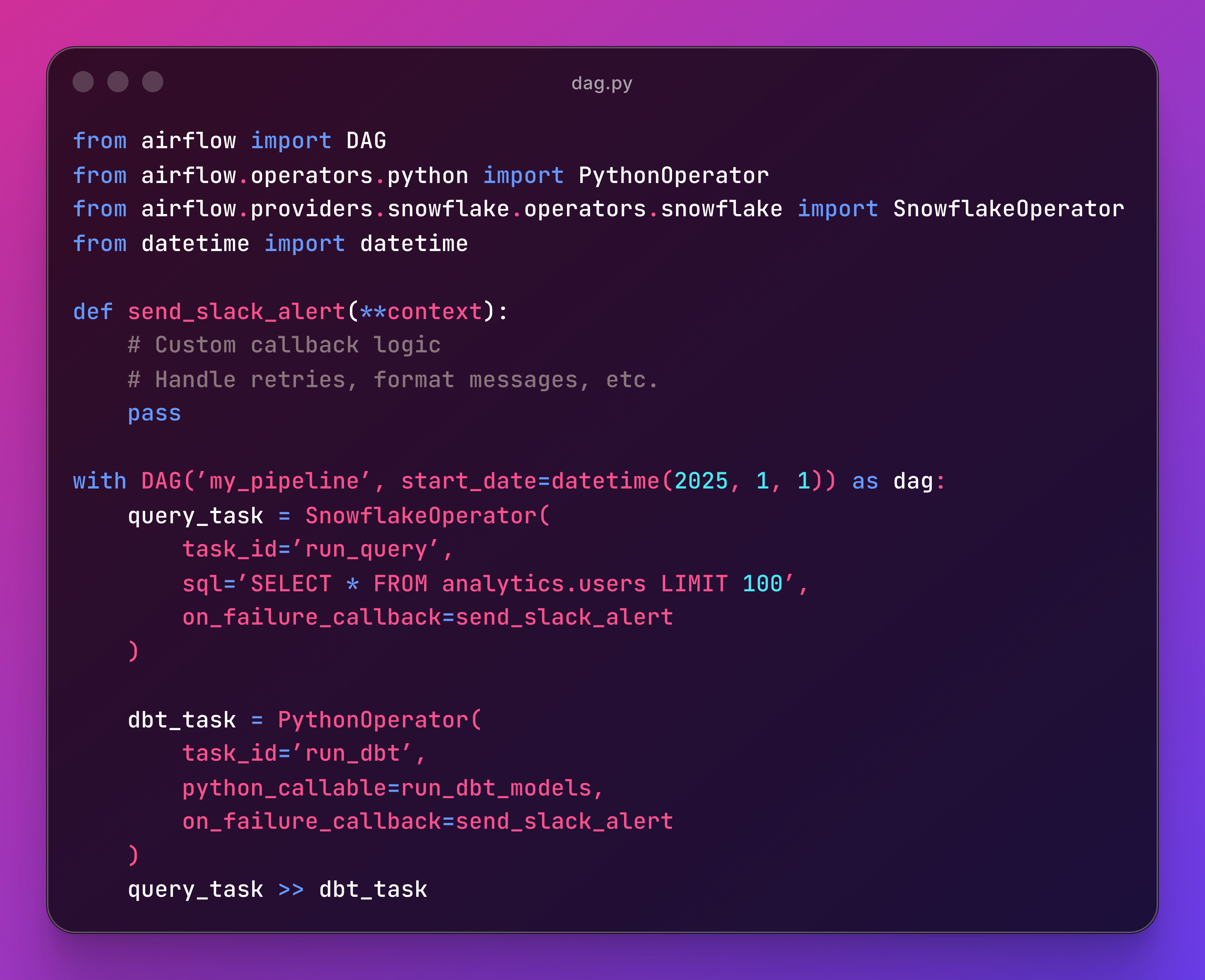
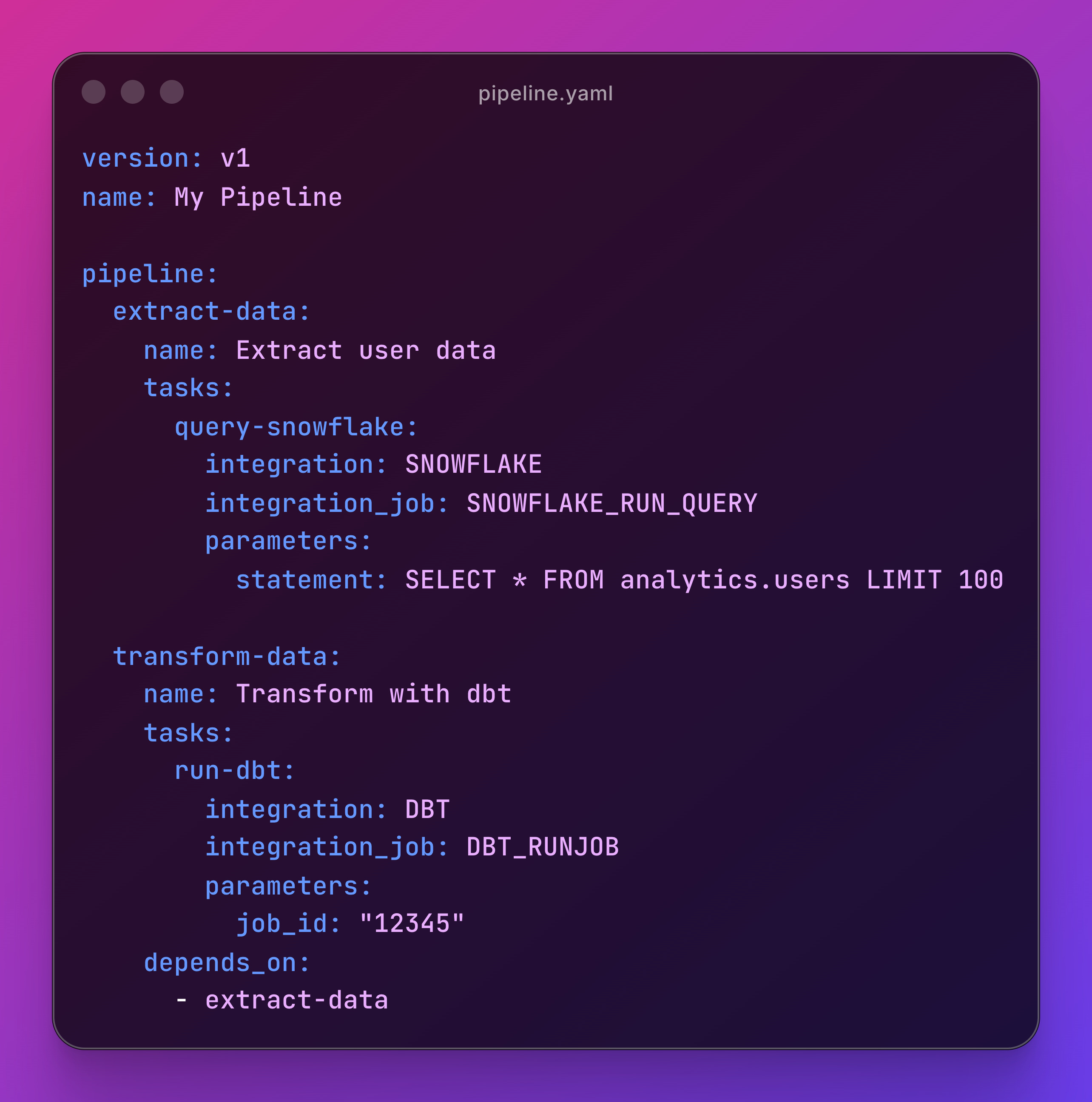
Let’s put the code side by side.
Traditional Airflow DAG:
Orchestra equivalent:
⚡ Beyond All This
Orchestra is not limited to its UI to build pipelines, you can handle your own version control configuration with YAMLs, set up AI workflows and use its MCP to leverage all the features from the outisde:
GitHub integration via GitBridge. Every pipeline is a YAML file. PRs review workflows like code.
Orchestra MCP and Docs-As-MCP for your YAML coding. Any AI IDE can follow Docs guideline to avoid broken YAML configs.
Pre-built Agentic Workflows for dbt impact analysis, slack custom reports, data enrichment, and whatever other custom use case you might want to cover.
Resources: Github Integration | Agentic Workflows | Orchestra MCP | Docs-As-MCP
🤔 When to Use Orchestra
Let me be clear: Orchestra isn’t for everyone.
Do use Orchestra if:
You’re tired of maintaining orchestration infrastructure
You want observability without the overhead
Your workflows are primarily about coordinating external tools (dbt, Snowflake, Databricks, Fivetran, etc.)
You value developer velocity over maximum flexibility
You want to focus on data pipelines, not pipeline tooling
Don’t use Orchestra if:
You need complete control over compute (e.g., custom Kubernetes operators)
Your team is heavily Python-centric and prefers code over config
You have extremely complex, programmatic orchestration logic that can’t be expressed declaratively
You’re already running Airflow successfully and have no pain points
📝 Final Words
For years, Airflow was the default choice for orchestration. But the landscape has changed. I’m not saying Airflow is dead. It’s still the right choice for many teams. But if you’re starting from scratch or feeling the Airflow tax, Orchestra is worth a look.
The orchestration layer shouldn’t be your bottleneck. It should be invisible ;)
If you enjoyed the content, hit the like ❤️ button, share, comment, repost, and all those nice things people do when like stuff these days. Glad to know you made it to this part!

Hi, I am Alejandro Aboy. I am currently working as a Data Engineer. I started in digital marketing at 19. I gained experience in website tracking, advertising, and analytics. I also founded my agency. In 2021, I found my passion for data engineering. So, I shifted my career focus, despite lacking a CS degree. I’m now pursuing this path, leveraging my diverse experience and willingness to learn.